ML and NLP Research Highlights of 2020
This post summarizes progress in 10 exciting and impactful directions in ML and NLP in 2020.

The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). I tried to cover the papers that I was aware of but likely missed many relevant ones—feel free to highlight them in the comments below. In all, I discuss the following highlights:
- Scaling up—and down
- Retrieval augmentation
- Few-shot learning
- Contrastive learning
- Evaluation beyond accuracy
- Practical concerns of large LMs
- Multilinguality
- Image Transformers
- ML for science
- Reinforcement learning
1) Scaling up—and down
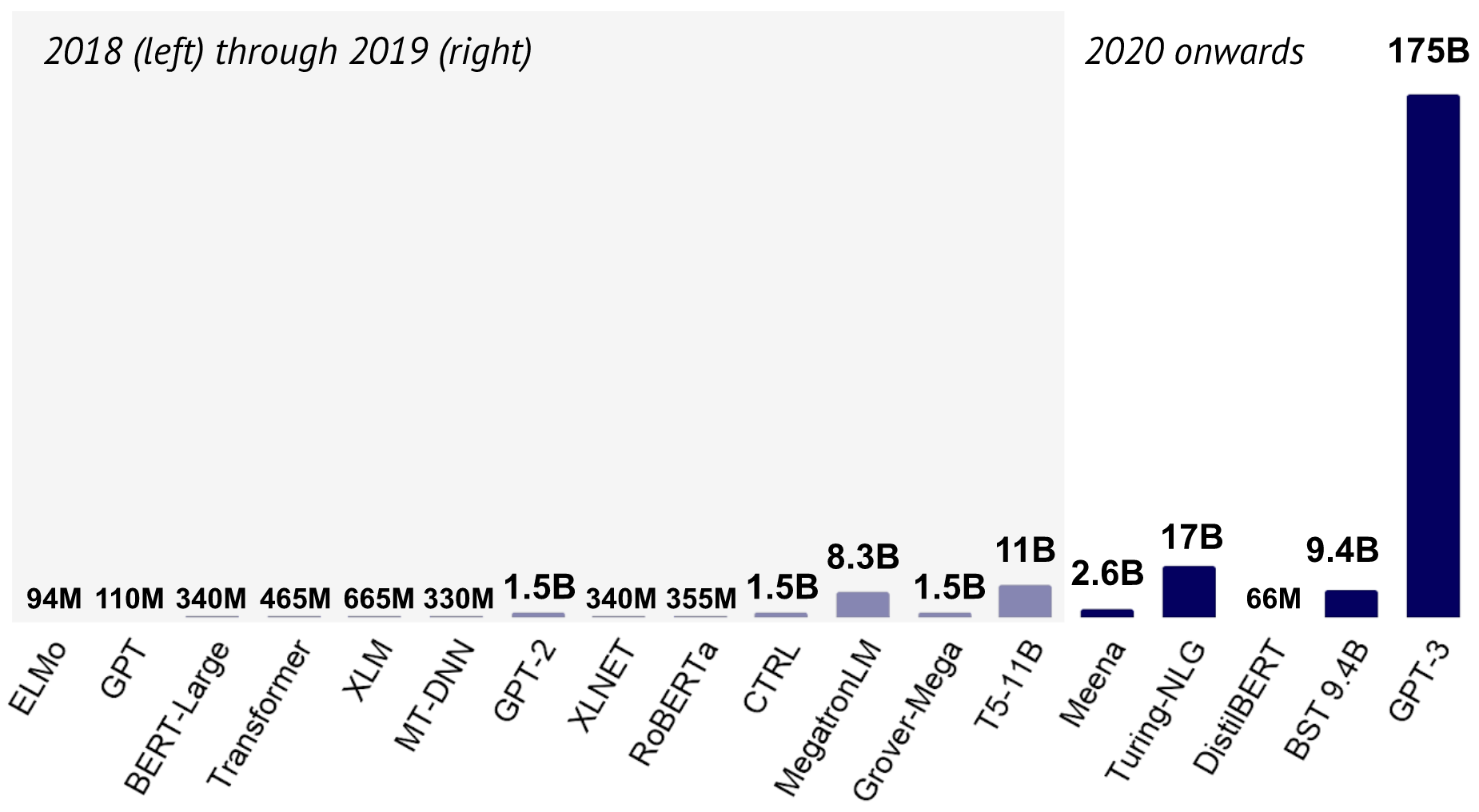
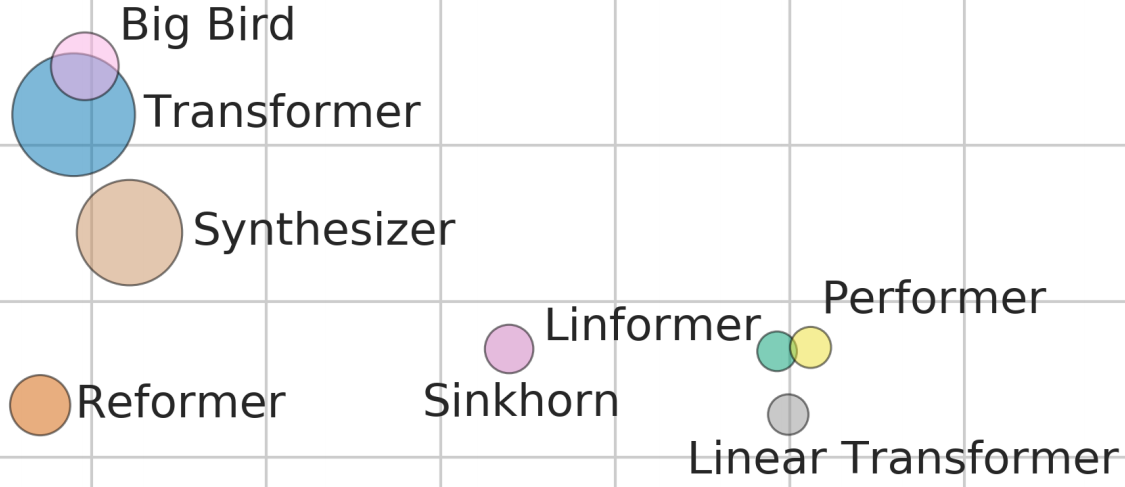
What happened? 2020 saw the development of ever larger language and dialogue models such as Meena (Adiwardana et al., 2020), Turing-NLG, BST (Roller et al., 2020), and GPT-3 (Brown et al., 2020). At the same time, researchers have become more aware of how expensive and energy-hungry these models can be (Strubell et al., 2019) and work that focuses on making them smaller has gained momentum: Recent approaches rely on pruning (Sajjad et al., 2020; Fan et al., 2020a; Sanh et al., 2020), quantization (Fan et al., 2020b), distillation (Sanh et al., 2019; Sun et al., 2020), and compression (Xu et al., 2020). Other approaches focused on making the Transformer architecture itself more efficient. Models in this line include the Performer (Choromanski et al., 2020) and Big Bird (Zaheer et al., 2020), which can be seen in the cover image above. The image shows performance (y axis), speed (x axis) and memory footprint (circle size) of different models on the Long Range Arena benchmark (Tay et al., 2020).
Tools such as the experiment-impact-tracker (Henderson et al., 2020) have made it easier to track the energy efficiency of models. They have also facilitated competitions and benchmarks that evaluate models primarily based on their efficiency such as the SustaiNLP workshop at EMNLP 2020, the Efficient QA competition at NeurIPS 2020, and HULK (Zhou et al., 2020).
Why is it important? Scaling up models allows us to keep pushing the boundaries of what current models can do. In order to deploy and use them in real-world scenarios, however, they need to be efficient. Ultimately, both directions benefit each other: Compressing large models yields efficient models with strong performance (Li et al., 2020) while more efficient methods may lead to stronger, larger models (Clark et al., 2020).
What's next? I am hopeful that—in light of the increasing interest in efficiency and the availability of tools—it will become more common not only to report a model's performance and number of parameters but also its energy efficiency. This should contribute to a more holistic evaluation that may help to bridge the gap to real-world ML use cases.
2) Retrieval augmentation
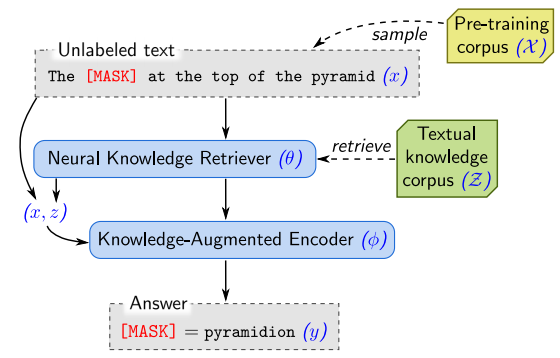
What happened? Large models have been shown to have learned a surprising amount of world knowledge from their pre-training data, which allows them to reproduce facts (Jiang et al., 2020) and answer questions even without access to external context (Roberts et al., 2020). However, storing such knowledge implicitly in the parameters of a model is inefficient and requires ever larger models to retain more information. Instead, recent approaches jointly trained retrieval models and large language models, which led to strong results on knowledge-intensive NLP tasks such as open-domain question answering (Guu et al., 2020; Lewis et al., 2020) and language modelling (Khandelwal et al., 2020). The main advantage of these methods is that they integrate retrieval directly into language model pre-training, which allows language models to be much more efficient by being able to off-load the recall of facts and focus on learning the more challenging aspects of natural language understanding. Consequently, the best systems in the NeurIPS 2020 EfficientQA competition (Min et al., 2020) all relied on retrieval.
Why is it important? Retrieval was the standard in many generative tasks, such as text summarization or dialogue and has largely been superseded by abstractive generation (Allahyari et al., 2017). Retrieval-augmented generation enables combining the best of both worlds: the factual correctness and faithfulness of retrieved segments and the relevancy and composition of generated text.
What's next? Retrieval-augmented generation should be particularly useful for dealing with failure cases that have plagued generative neural models in the past, such as dealing with hallucinations (Nie et al., 2019). It may also help make systems more interpretable by directly providing evidence for their prediction.
3) Few-shot learning

What happened? Over the last years, driven by advances in pre-training, the number of training examples to perform a given task has progressively gone down (Peters et al., 2018; Howard et al., 2018). We are now at a stage where tens of examples can be used to demonstrate a given task (Bansal et al., 2020). A very natural paradigm for few-shot learning is to reframe a task as language modelling. The most prominent instantiation of this, the in-context learning approach of GPT-3 (Brown et al., 2020) performs a prediction based on a few demonstrations of input–output pairs in the model's context and a prompt without any gradient updates. This setting, however, has a few limitations: It requires a huge model—without any updates the model needs to rely on its existing knowledge—, the amount of knowledge that the model can use is restricted by its context window, and prompts need to be hand-engineered.
Recent work has sought to make such few-shot learning more effective by using a smaller model, integrating fine-tuning, and automatically generating natural language prompts (Schick and Schütze, 2020; Gao et al., 2020; Shin et al., 2020). Such work is closely related to the broader area of controllable neural text generation, which broadly seeks to leverage the generative capabilities of powerful pre-trained models. For an excellent overview, check out Lilian Weng's blog post.
Few-shot learning enables rapid adaptation of a model to many tasks. However, updating all model parameters for each task is wasteful. Instead, it is preferable to perform localized updates that concentrate changes in a small set of parameters. There have been a few approaches that make such efficient fine-tuning more practical including using adapters (Houlsby et al., 2019; Pfeiffer et al., 2020a,b; Üstün et al., 2020), adding a sparse parameter vector (Guo et al., 2020), and only modifying bias values (Ben-Zaken et al., 2020).
Why is it important? Being able to teach a model a task based on only a few examples greatly reduces the barrier to entry for applying ML and NLP models in practice. This opens up applications where data is very expensive to collect and enables adapting models swiftly to new domains.
What's next? For many real-world scenarios, it is possible to collect thousands of training examples. Models should thus be able to scale seamlessly from learning from a few to learning from thousands of examples and should not be limited by e.g. their context length. Given that models have achieved super-human performance on many popular tasks such as SuperGLUE when fine-tuned on entire training datasets, enhancing their few-shot performance is a natural area for improvement.
4) Contrastive learning
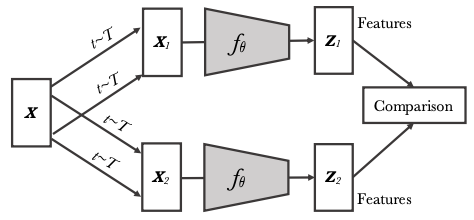
What happened? Contrastive learning—learning to differentiate a positive example from negative samples, often from a noise distribution—such as using negative sampling or noise contrastive estimation is a staple of representation learning and self-supervised learning and a prominent part of classic approaches such as word2vec (Mikolov et al., 2013). More recently, contrastive learning gained popularity in self-supervised representation learning in computer vision and speech (van den Oord, 2018; Hénaff et al., 2019). The recent generation of increasingly powerful self-supervised approaches for visual representation learning rely on contrastive learning using an instance discrimination task: different images are treated as negative pairs and views of the same image are treated as positive pairs. Recent approaches have further refined this general framework: SimCLR (Chen et al., 2020) defines the contrastive loss over augmented examples, Momentum Contrast (He et al., 2020) seeks to ensure a large and consistent set of pairs, SwAV (Caron et al., 2020) leverages online clustering, and BYOL only employs positive pairs (Grill et al., 2020). Chen and He (2020) have furthermore proposed a simpler formulation that relates to the previous methods.
Recently, Zhao et al. (2020) find that data augmentation is essential for contrastive learning. This might indicate why unsupervised contrastive learning has not been successful with large pre-trained models in NLP where data augmentation is less common. They also hypothesize that the reason instance discrimination may work better than supervised pre-training in computer vision is that it does not try to make the features of all instances from a class similar but retains the information from each instance. This is less of a problem in NLP where unsupervised pre-training involves classification over thousands of word types. In NLP, Gunel et al. (2020) recently employ contrastive learning for supervised fine-tuning.
Why is it important? The cross-entropy objective between one-hot labels and a model's output logits commonly used in language modelling has several limitations such as generalizing poorly to imbalanced classes (Cao et al., 2019). Contrastive learning is an alternative, complementary paradigm that may help ameliorate some of these deficits.
What's next? Contrastive learning combined with masked language modelling may enable us to learn representations that are richer and more robust. It could help model outliers and rare syntactic and semantic phenomena, which are a challenge for current NLP models.
5) Evaluation beyond accuracy

What happened? State-of-the-art models in NLP have achieved superhuman performance across many tasks. Whether or not we believe that such models can achieve true natural language understanding (Yogatama et al., 2019; Bender and Koller, 2020), we know that current models are not close to this elusive goal. However, the simple performance metrics of our tasks fail to capture the limitations of existing models. There are two key themes in this area: a) curating examples that are difficult for current models; and b) going beyond simple metrics such as accuracy towards more fine-grained evaluation.
Regarding the former, the common methodology is to use adversarial filtering (Zellers et al., 2018) during dataset creation to filter out examples that are predicted correctly by current models. Recent work proposes more efficient adversarial filtering methods (Sakaguchi et al., 2020; Le Bras et al., 2020) and an iterative dataset creation process (Nie et al., 2020; Bartolo et al., 2020) where examples are filtered and models are re-trained over multiple rounds. A subset of such evolving benchmarks are available in Dynabench.
The methods that regard the second point are similar in spirit. However, rather than creating examples that target a specific model, examples are used to probe for phenomena common to a task of interest. Commonly, minimal pairs—also known as counterfactual examples or contrast sets—(Kaushik et al., 2020; Gardner et al., 2020; Warstadt et al., 2020) are created, which perturb examples in a minimal way and often change the gold label. Ribeiro et al. (2020) formalized some of the underlying intuitions in their CheckList framework, which enables the semi-automatic creation of such test cases. Alternatively, examples can be characterized based on different attributes, which allow a more fine-grained analysis of a model's strengths and weaknesses (Fu et al., 2020).
Why is it important? In order to make meaningful progress towards building more capable models machine learning models, we need to understand not only if a model outperforms a previous system but what kind of errors it makes and which phenomena it fails to capture.
What's next? By providing fine-grained diagnostics of model behaviour, it will be easier to identify a model's deficiencies and propose improvements that address them. Similarly, a fine-grained evaluation would allow a more nuanced comparison of the strengths and weaknesses of different methods.
6) Practical concerns of large LMs
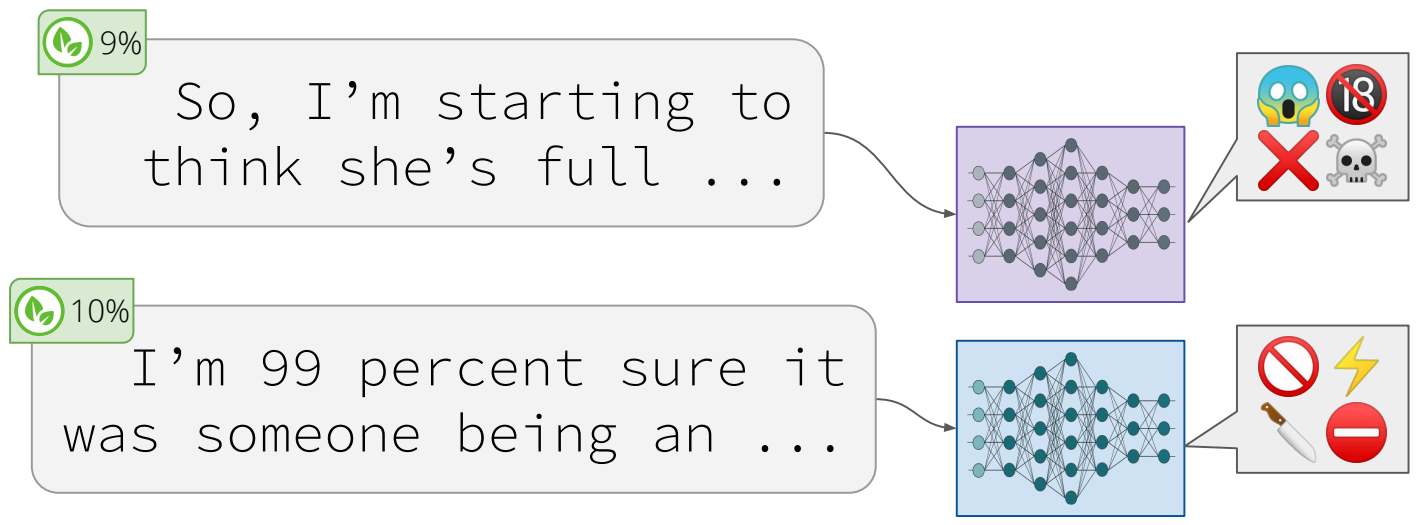
What happened? Compared to 2019 where the analysis of language models (LMs) mainly focused on the syntactic, semantic, and world knowledge that such models capture—see (Rogers et al., 2020) for a great overview—recent analyses revealed a number of practical concerns. Pre-trained language models were found to be prone to generating toxic language (Gehman et al., 2020) and leak information (Song & Raghunathan, 2020), to be susceptible to backdoors after fine-tuning, which let an attacker manipulate the model prediction (Kurita et al., 2020; Wallace et al., 2020), and to be vulnerable to model and data extraction attacks (Krishna et al., 2020; Carlini et al., 2020). In addition, pre-trained models are well known to capture biases with regard to protected attributes such as gender (Bolukbasi et al., 2016; Webster et al., 2020)—see (Sun et al., 2019) for an excellent survey on mitigating gender bias.
Why is it important? Large pre-trained models are trained by many institutions and are actively deployed in real-world scenarios. It is thus of practical importance that we are not only aware of their biases but what behaviour may have actually harmful consequences.
What's next? As larger and more powerful models are developed, it is important that such practical concerns as well as issues around bias and fairness are part of the development process from the start.
7) Multilinguality
What happened? 2020 had many highlights in multilingual NLP. The Masakhane organisation whose mission is to strengthen NLP for African languages gave the keynote at the Fifth Conference on Machine Translation (WMT20), one of the most inspiring presentations of the last year. New general-purpose benchmarks for other languages emerged including XTREME (Hu et al., 2020), XGLUE (Liang et al., 2020), IndoNLU (Wilie et al., 2020), IndicGLUE (Kakwani et al., 2020). Existing datasets that were replicated in other languages—together with their non-English variants—include:
- SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020);
- Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
- MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
- the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020); and
- the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020).
Many of these datasets and many others in different languages are easily accessible via Hugging Face datasets. Powerful multilingual models that cover around 100 languages emerged including XML-R (Conneau et al., 2020), RemBERT (Chung et al., 2020), InfoXLM (Chi et al., 2020), and others (see the XTREME leaderboard for an overview). A plethora of language-specific BERT models have been trained for languages beyond English such as AraBERT (Antoun et al., 2020) and IndoBERT (Wilie et al., 2020); see (Nozza et al., 2020; Rust et al., 2020) for an overview. With efficient multilingual frameworks such as AdapterHub (Pfeiffer et al., 2020), Stanza (Qi et al., 2020) and Trankit (Nguyen et al., 2020) it has become easier than ever to apply and build models for many of the world's languages.
Finally, two position papers that inspired much of my thinking in this area this year are The State and Fate of Linguistic Diversity and Inclusion in the NLP World (Joshi et al., 2020) and Decolonising Speech and Language Technology (Bird, 2020). While the first highlights the urgent importance of working on languages beyond English, the second one cautions against treating language communities and their data as a commodity.
Why is it important? Working on NLP beyond English has numerous benefits: It poses interesting challenges for ML and NLP and enables having a large impact on society, among many others.
What's next? Given the availability of data and models in different languages, the stage is set to make meaningful progress on languages beyond English. I am most excited about developing models that tackle the most challenging settings and identifying in which cases the assumptions that underlie our current models fail.
8) Image Transformers
What happened? While Transformers have achieved large success in NLP, they were—up until recently—less successful in computer vision where convolutional neural networks (CNNs) still reigned supreme. While models early in the year such as DETR (Carion et al., 2020) employed a CNN to compute image features, later models were completely convolution-free. Image GPT (Chen et al., 2020) applied the GPT-2 recipe to pre-training directly from pixels and outperforms a supervised Wide ResNet. Later models all reshape an image into patches that are treated as "tokens". Vision Transformer (Dosovitskiy et al., 2020) is pre-trained on millions of labelled images—each consisting of such patches—outperforming state-of-the-art CNNs. The Image Processing Transformer (Chen et al., 2020) pre-trains on corrupted ImageNet examples with a contrastive loss and achieves state-of-the-art performance on low-level image tasks. The Data-efficient image Transformer (Touvron et al., 2020) is pre-trained on ImageNet via distillation. Interestingly, they observe that CNNs are better teachers. This is similar to findings for distilling an inductive bias into BERT (Kuncoro et al., 2020). In contrast in speech, Transformers have not been applied directly to the audio signal—to my knowledge—but typically receive the output of an encoder such as a CNN as input (Moritz et al., 2020; Gulati et al., 2020; Conneau et al., 2020)
Why is it important? Transformers have less inductive bias compared to CNNs and RNNs. While being less theoretically powerful than RNNs (Weiss et al., 2018; Hahn et al., 2020), given sufficient data and scale Transformers have been shown to eventually outperform their inductively biased competitors (cf. The Bitter Lesson).
What's next? We will likely see Transformers become more popular in computer vision. They will be applied particularly in scenarios where enough compute and data for unsupervised pre-training is available. In smaller scale settings, CNNs will likely still be the go-to approach and a strong baseline.
9) ML for science
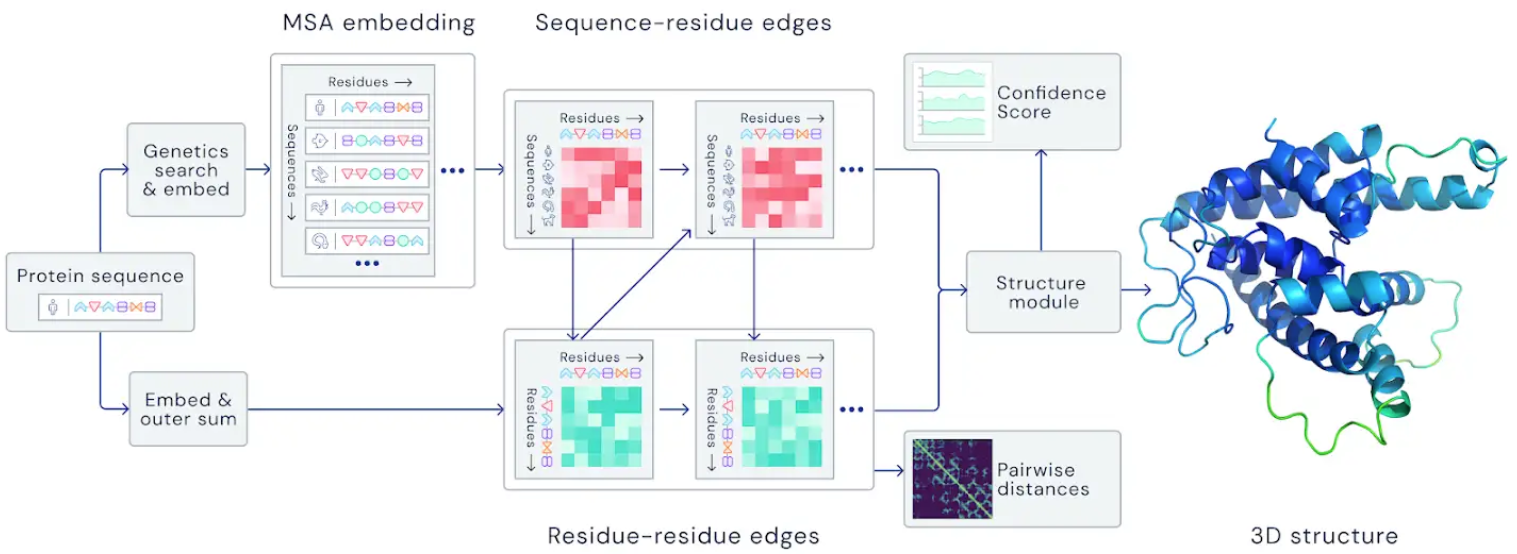
What happened? One of the highlights was AlphaFold demonstrating ground-breaking performance in the biannual CASP challenge for protein folding. Beyond that, there have been several other notable developments in applying ML to problems in the natural sciences. MetNet (Sønderby et al., 2020) outperformed numerical weather prediction for precipitation forecasting, Lample and Charton (2020) solved differential equations using neural networks better than commercial computer algebra systems, and Bellemare et al. (2020) used reinforcement learning to navigate balloons in the stratosphere.
In addition, ML has been used extensively to help with the ongoing COVID-19 pandemic, e.g. to forecast COVID-19 spread (Kapoor et al., 2020), predict structures associated with COVID-19, translate relevant data into 35 different languages (Anastasopoulos et al., 2020), and answer questions about COVID-19 in real-time (Lee et al., 2020). For an overview of COVID-19 related applications of NLP, check out the Proceedings of the 1st Workshop on NLP for COVID-19.
Why is it important? The natural sciences are arguably the most impactful application area for ML. Improvements touch many aspects of life and can have a profound impact on the world.
What's next? With progress in areas as central as protein folding, the speed of application of ML to the natural sciences will only accelerate. I am looking forward to many more fundamental advances that have a positive impact in the world.
10) Reinforcement learning
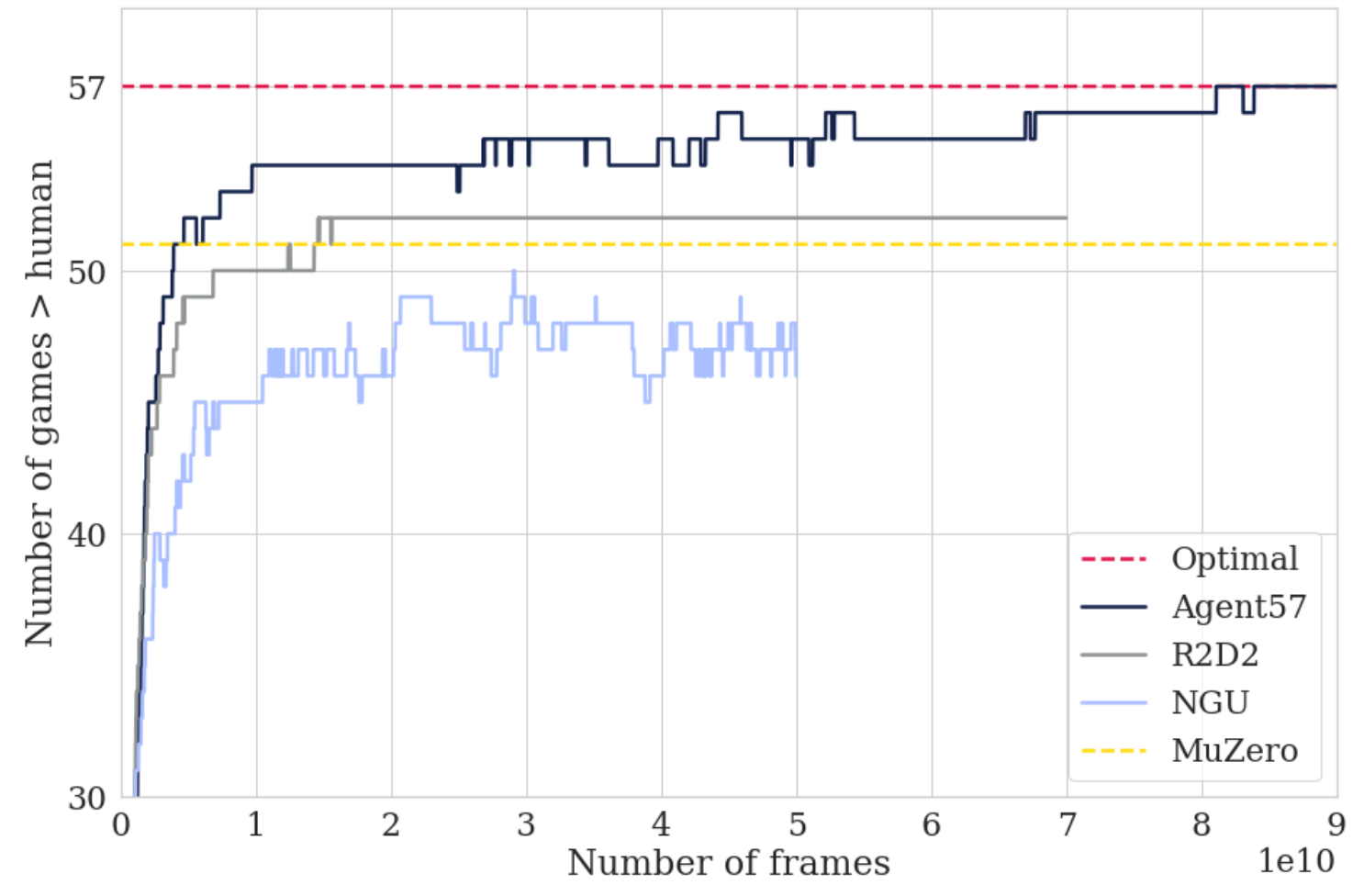
What happened? For the first time, a single deep RL agent—Agent57 (Badia et al., 2020)—has achieved superhuman performance on all 57 Atari games, a long-standing benchmark in the deep reinforcement learning literature. The agent's versatility comes from a neural network that allows it to switch between exploratory and exploitative policies. Another milestone was the development of MuZero (Schrittwieser et al., 2020), which predicts the aspects of the environment that are most important for accurate planning. Without any knowledge of the game dynamics, it achieved state-of-the-art performance on Atari as well as superhuman performance on Go, chess, and shogi. Finally, Munchausen RL agents (Vieillard et al., 2020) improved on state-of-the-art agents via a simple, theoretically founded modification.
Why is it important? Reinforcement learning algorithms have a multitude of practical implications (Bellemare et al., 2020). Improvements over the fundamental algorithms in this area can have a large practical impact by enabling better planning, environment modelling, and action prediction.
What's next? With classic benchmarks such as Atari essentially solved, researchers may look to more challenging settings to test their algorithms such as generalizing to out-of-distribution tasks, improving sample-efficiency, multi-task learning, etc.
Citation
For attribution in academic contexts, please cite this work as:
@misc{ruder2021researchhighlights,
author = {Ruder, Sebastian},
title = {{ML and NLP Research Highlights of 2020}},
year = {2021},
howpublished = {\url{http://ruder.io/research-highlights-2020}},
}Thanks to Sameer Singh whose Twitter thread reviewing NLP research in 2020 provided inspiration for this post.