Multi-domain Multilingual Question Answering
This post expands on the EMNLP 2021 tutorial on Multi-domain Multilingual Question Answering and highlights key insights and takeaways.

This post expands on the EMNLP 2021 tutorial on Multi-domain Multilingual Question Answering.
The tutorial was organised by Avi Sil and me. In this post, I highlight key insights and takeaways of the tutorial. The slides are available online. You can find the table of contents below:
Introduction
Question answering is one of the most impactful tasks in natural language processing (NLP). In the tutorial, we focus on two main categories of question answering studied in the literature: open-retrieval question answering (ORQA) and reading comprehension (RC).
Open-Retrieval QA vs Reading Comprehension
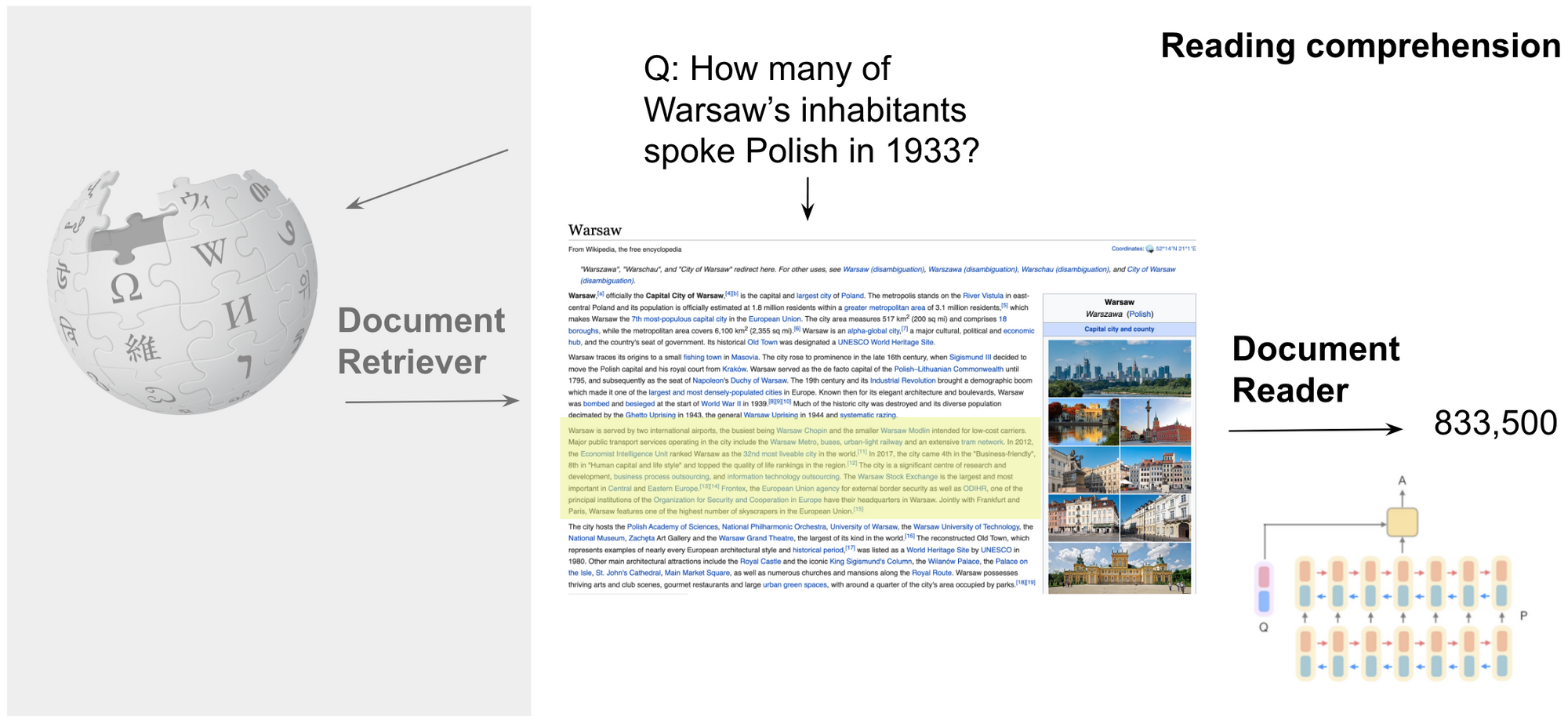
Open-retrieval QA focuses on the most general setting where given a question we first need to retrieve relevant documents from a large corpus such as Wikipedia. We then process these documents to identify the relevant answer as can be seen below. We avoid using the term open-domain QA as "open-domain" may also refer to a setting covering many domains.

Reading comprehension can be seen as a sub-problem of open-retrieval QA as it assumes that we have access to the gold paragraph that contains the answer (see below). We then only need to find the corresponding answer in this paragraph. In both settings, answers are commonly represented as a minimal span.
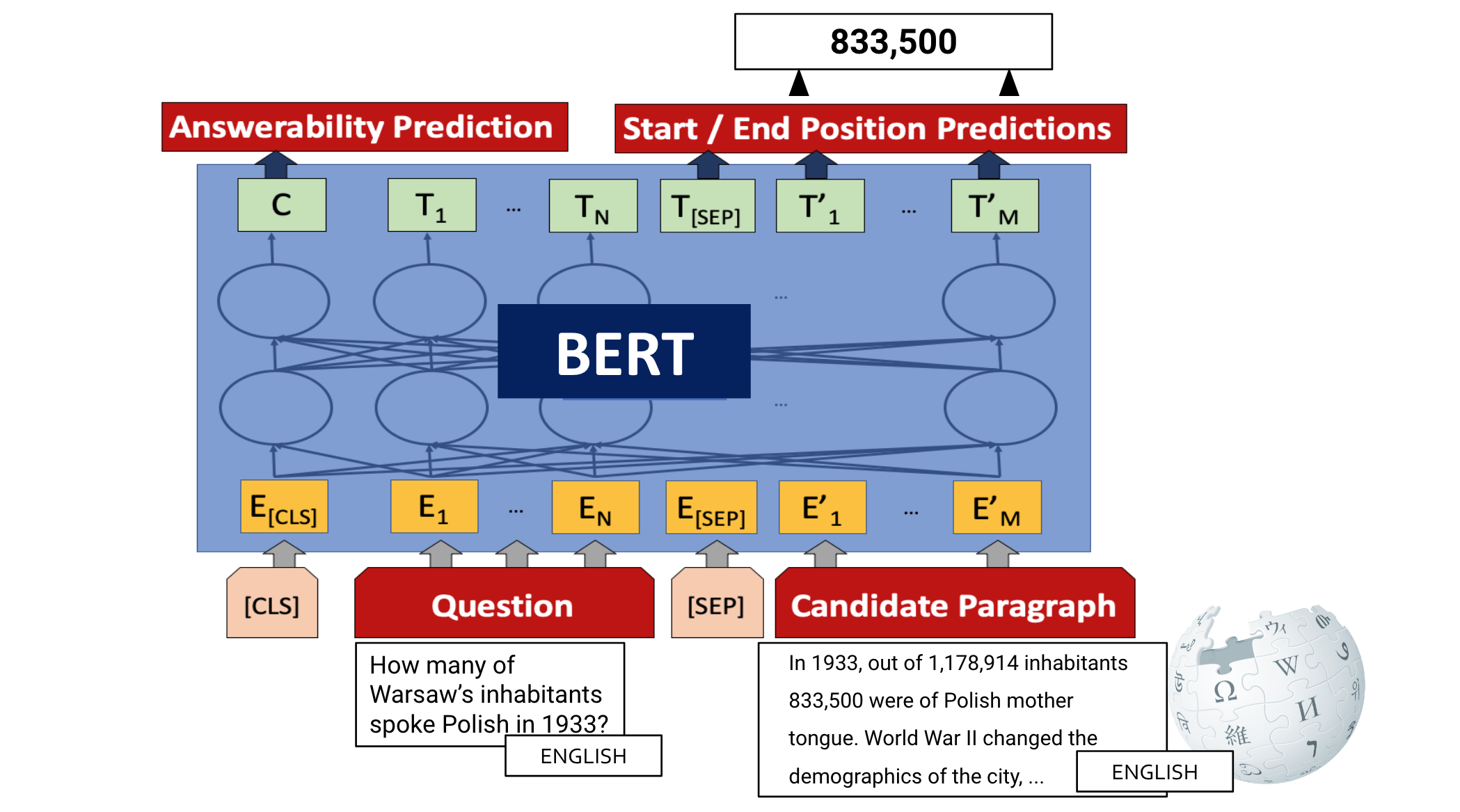
Standard approaches for reading comprehension build on pre-trained models such as BERT. The model is provided with the question and candidate paragraph as input and is trained to predict whether the question is answerable (typically using the representation associated with its [CLS] token) and whether each token is the start or end of an answer span, which can be seen below. The same approach can be used for ORQA, with some modifications (Alberti et al., 2019).
Information retrieval (IR) methods are used to retrieve the relevant paragraphs. Classic sparse methods such as BM25 (Robertson et al., 2009) do not require any training as they weigh terms and documents based on their frequency using tf-idf measures. Recent dense neural approaches such as DPR (Karpukhin et al., 2020) train models to maximize the similarity between question and passage and then retrieve the most relevant passages via maximum inner product search.
What is a Domain?
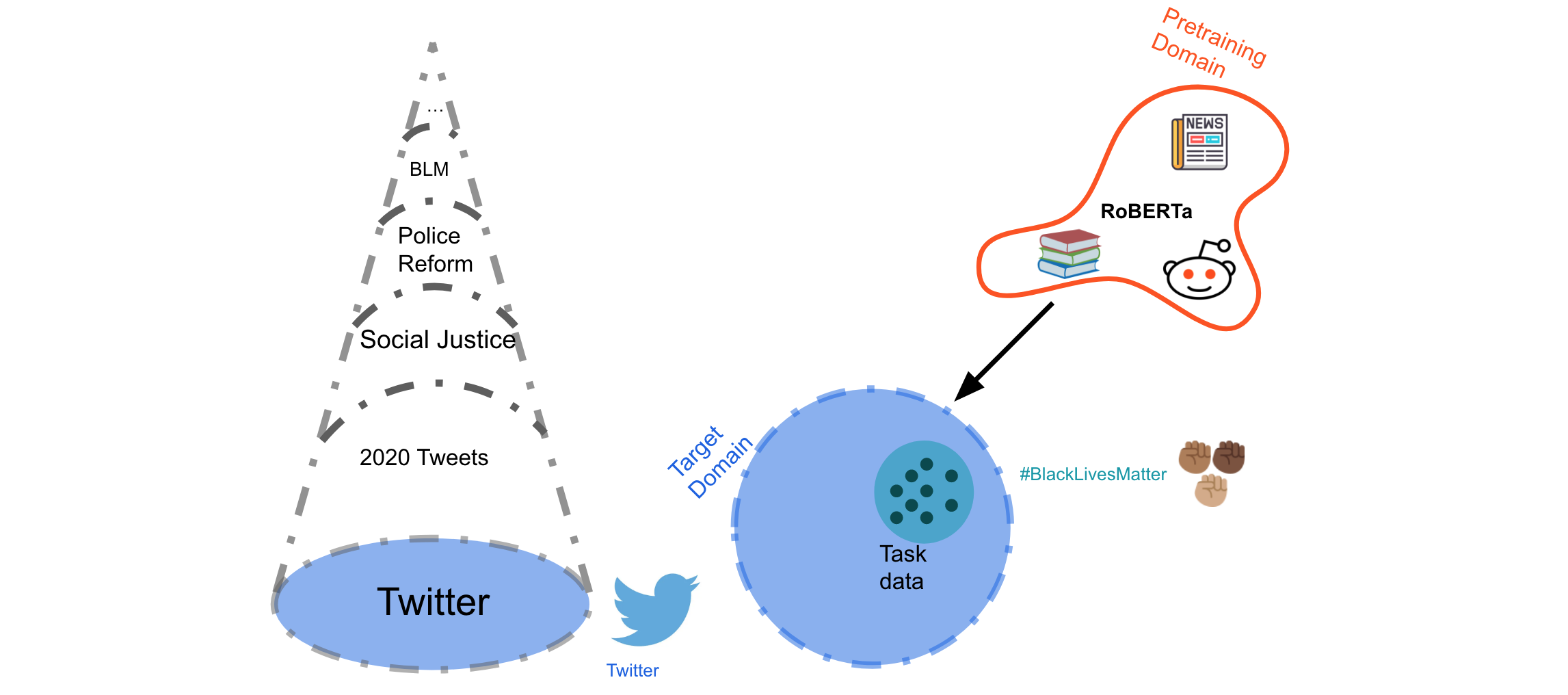
A domain can be seen as a manifold in a high-dimensional variety space consisting of many dimensions such as socio-demographics, language, genre, sentence type, etc (Plank et al., 2016). Domains differ in terms of their granularity and large domains such as Twitter can consist of several more narrow domains to which we might want to adapt our models. Two major facets of this variety space are genre (we will use this term interchangeably with 'domain') and language, which will be the focus of this post.
Multi-Domain QA
In each of the two main sections of this post, we will first discuss common datasets and then modelling approaches.
Datasets for Multi-Domain QA
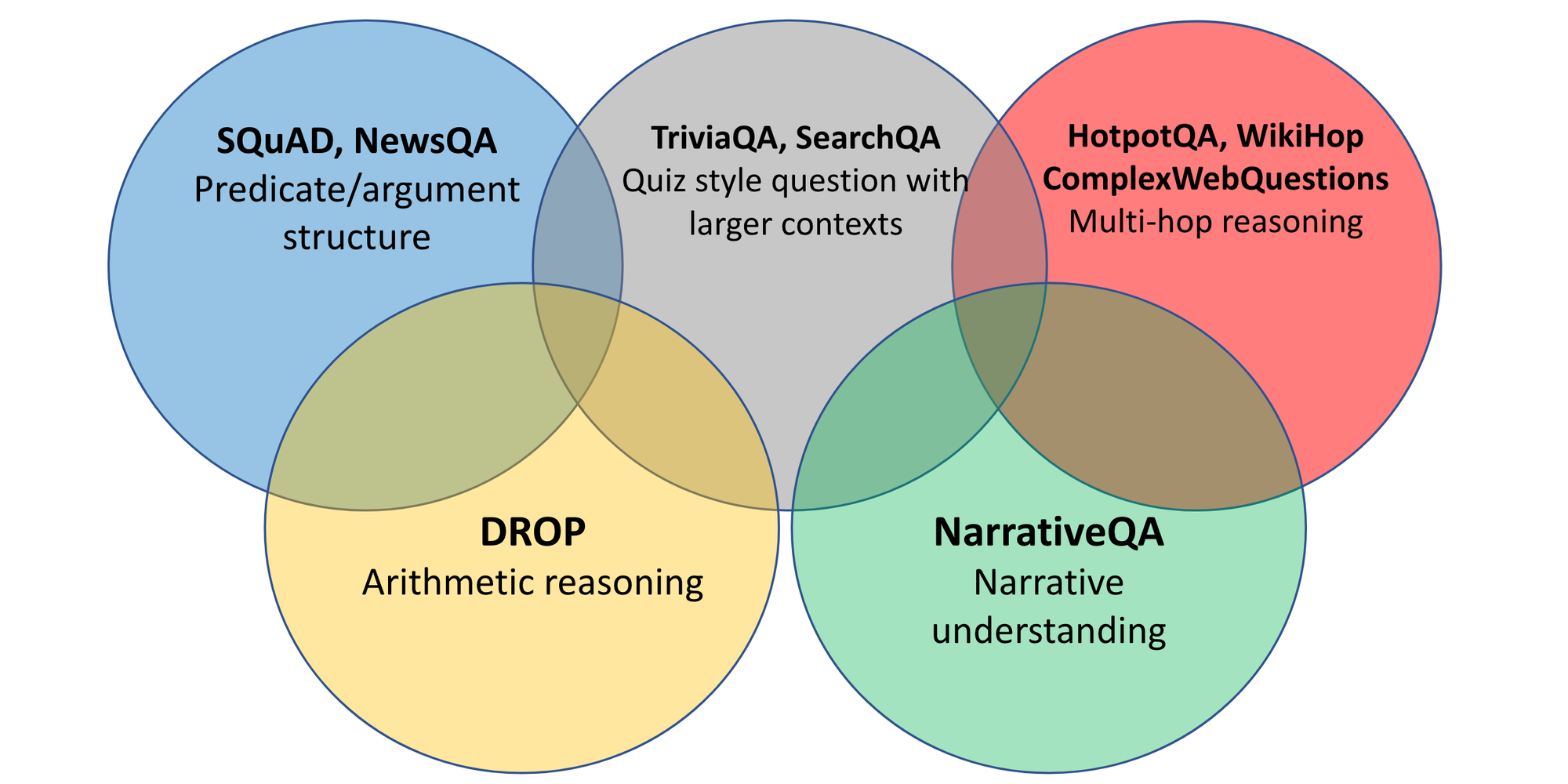
Research in question answering has spanned many domains, as can be seen below. The most common domain is Encyclopedia, which covers many Wikipedia-based datasets such as SQuAD (Rajpurkar et al., 2016), Natural Questions (NQ; Kwiatkowski et al., 2019), DROP (Dua et al., 2019), and WikiReading (Hewlett et al., 2016), among many others. Datasets in this domain are typically referred to as "open-domain" QA.
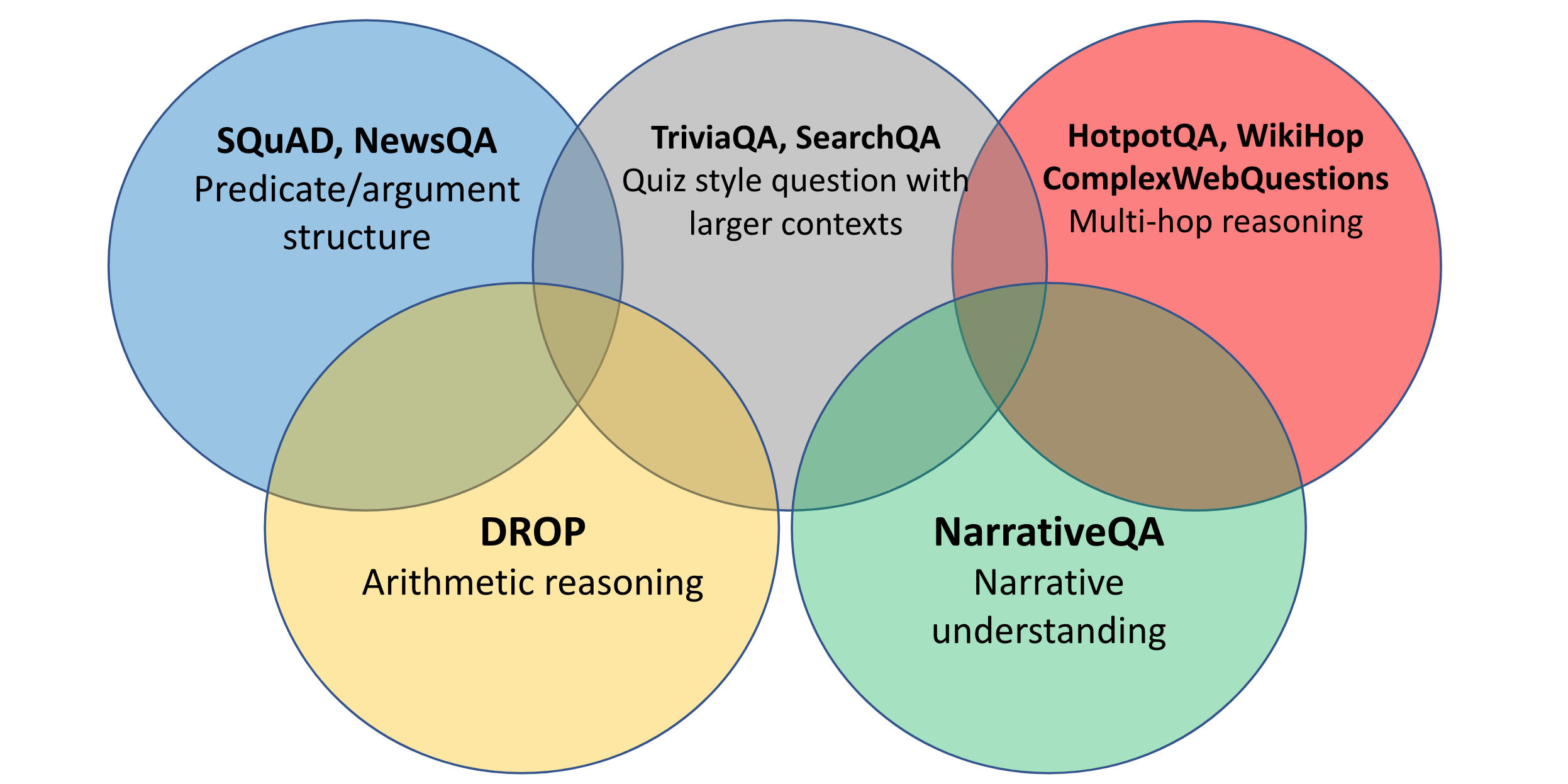
Datasets in the Fiction domain typically require processing narratives in books such as NarrativeQA (Kočiský et al., 2018), Children's Book Test (Hill et al., 2016), and BookTest (Bajgar et al., 2016) or narratives written by crowd workers such as MCTest (Richardson et al., 2013), MCScript (Modi et al., 2016), and ROCStories (Mostafazedh et al., 2016).
Academic tests datasets target science questions in US school tests such as ARC (Clark et al., 2018), college-level exam resources such as ReClor (Yu et al., 2019) and school-level exam resources such as RACE (Lai et al., 2017).
News datasets include NewsQA (Trischler et al., 2017), CNN / Daily Mail (Hermann et al., 2015), and NLQuAD (Soleimani et al., 2021).
In addition, there are datasets focused on Specialized Expert Materials including manuals, reports, scientific papers, etc. Such domains are most common in industry as domain-specific chatbots are increasingly used by companies to respond to users queries but associated datasets are rarely made available. Existing datasets focus on tech forums such as TechQA (Castelli et al., 2020) and AskUbuntu (dos Santos et al., 2015) as well as scientific articles including BioASQ (Tsatsaronis et al., 2015) and Qasper (Dasigi et al., 2021). In addition, the pandemic saw the creation of many datasets related to COVID-19 such as COVID-QA-2019 (Möller et al., 2020), COVID-QA-147 (Tang et al., 2020), and COVID-QA-111 (Lee et al., 2020).
Beyond these datasets focusing on individual domains, there are several datasets spanning multiple domains such as CoQA (Reddy et al., 2019), QuAIL (Rogers et al., 2020), and MultiReQA (Guo et al., 2021), among others. Lastly, the ORB evaluation server (Dua et al., 2019) enables the evaluation of systems across datasets spanning multiple domains.
Multi-Domain QA Models
In most cases when learning in a multi-domain setting there may be limited or no labelled data available in the target domain available. We discuss how to adapt to a target domain using only unlabelled data, the most effective way to use pre-trained language models for domain adaptation in QA, and how to generalize across domains.
Unsupervised Domain Adaptation for QA
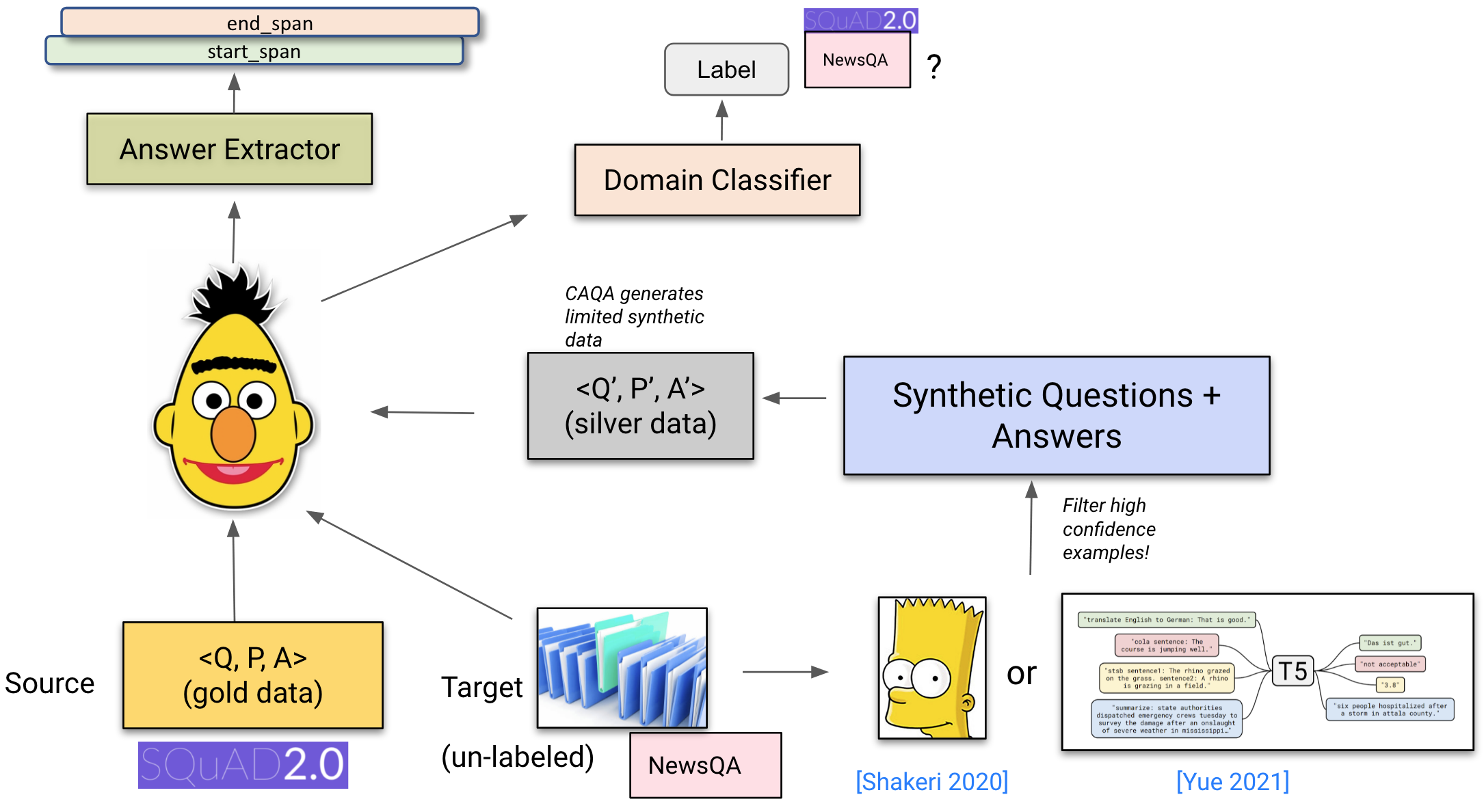
Unsupervised domain adaptation for QA assumes access to labelled data in a source domain and unlabelled target domain data. In the absence of labelled gold data in the target domain, most methods rely on generating 'silver' <question, paragraph, answer> data in the target domain. To this end, these methods train a question generation model based on a pre-trained LM on the source domain and then apply it to the target domain to generate synthetic questions given answer spans (Wang et al., 2019; Shakeri et al., 2020; Yue et al., 2021). The QA model is then trained jointly on the gold source domain and silver target domain data, as can be seen below. This is often combined with other domain adaptation strategies such as adversarial learning and self-training (Cao et al., 2020).
Domain Adaptation with Pre-trained LMs
In many scenarios with specialized domains, a general pre-trained language model such as BERT may not be sufficient. Instead, domain-adaptive fine-tuning (Howard & Ruder, 2018; Gururangan et al., 2020) of a pre-trained LM on target domain data typically performs better. Recent examples such as BioBERT (Lee et al., 2019) and SciBERT (Beltagy et al., 2019) have been effective for biomedical and scientific domains respectively.
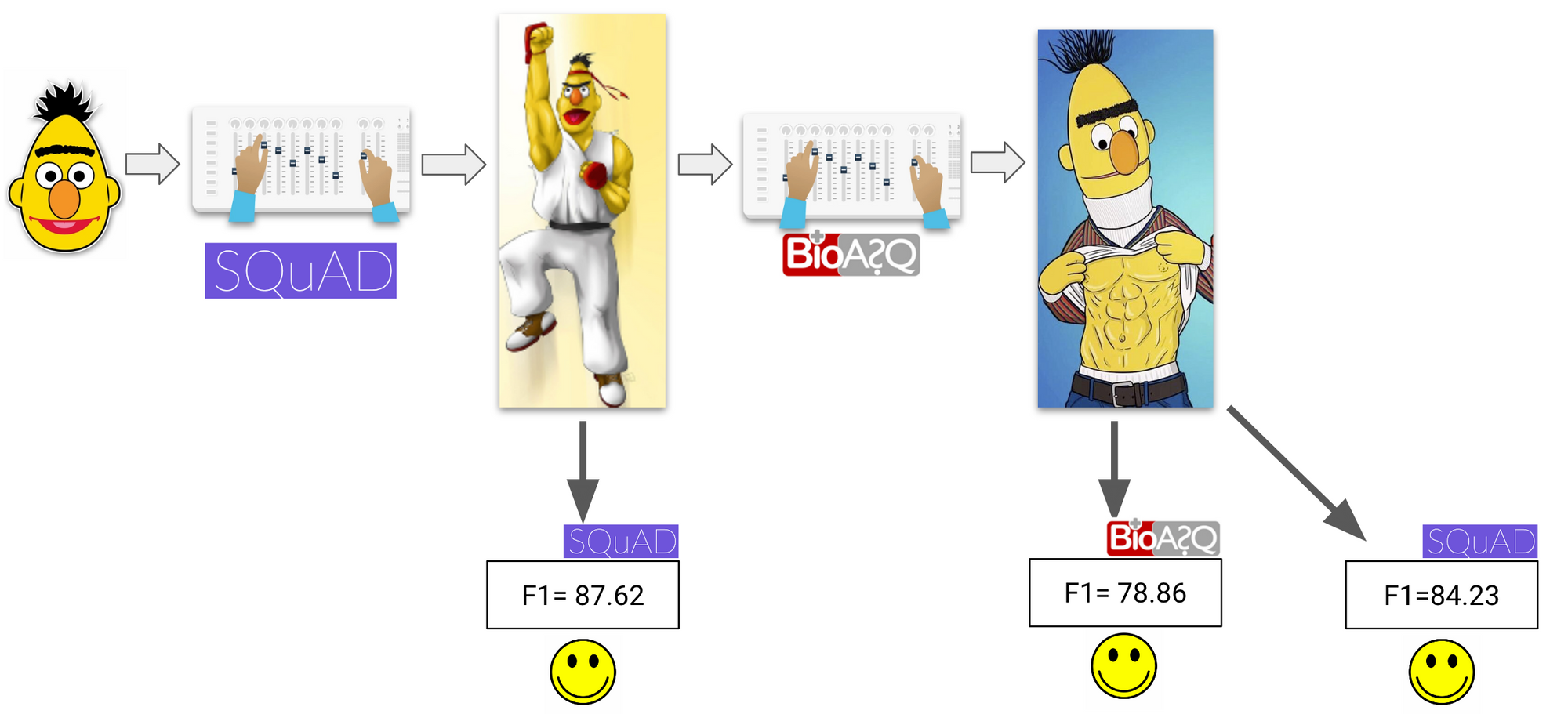
When labelled data in a source domain and in the target domain are available, a general recipe is to first fine-tune a model on labelled source domain data and then to subsequently fine-tune it on labelled data in the target domain. However, naive fine-tuning generally leads to deterioration of performance in the source domain, which may be undesirable. Instead, strategies from continual learning such as L2 regularization (Xu et al., 2019) ensure that the parameters of the model fine-tuned on the target domain do not diverge significantly from the source domain model, thereby reducing catastrophic forgetting as can be seen below.
For very low-resource domains, another strategy is to explicitly adapt the model to characteristics of the target domain. If the target domain contains specialized terms, the model's vocabulary can be augmented with these terms to learn better representations. In addition, for many domains, the structure of the unlabelled data can contain information that may be useful for the end task. This structure such as the abstract, error description, associated cause, etc can be leveraged to generate synthetic data on which the model can be fine-tuned (Zhang et al., 2020).
In the open-retrieval setting, dense retrieval methods (Karpukhin et al., 2020) trained on a source domain may not generalize in a zero-shot manner to low-resource target domains. Instead, we can leverage the same question generation methods discussed in the previous section to create silver data for training a retrieval model on the target domain (Reddy et al., 2021). Ensembling over BM25 and the adapted DPR model yields the best results.
Domain Generalization
In practice, pre-trained models fine-tuned on a single domain often generalize poorly. Training on multiple source distributions reduces the need for selecting a single source dataset (Talmor & Berant, 2019). Additional fine-tuning on a related task helps even when using pre-trained models.
However, different datasets often have different formats, which makes it difficult to train a joint model for them without task-specific engineering. Recent pre-trained LMs such as T5 facilitate such cross-dataset learning as each dataset can be converted to a unified text-to-text format. Training a model jointly across multiple QA datasets with such a text-to-text format leads to better generalization to unseen domains (Khashabi et al., 2020).
Multilingual QA
Language can be seen as another facet of the domain manifold. As we will see, many methods discussed in the previous section can also be successfully applied to the multilingual setting. At the same time, multilingual QA poses its own unique challenges.
Datasets for Multilingual QA
Many early multilingual IR and QA datasets have been collected as part of community evaluations. Many test collections used newswire articles, e.g. CLIR at TREC 1994–2004, QA at CLEF 2003–2005 (Magnini et al., 2003) or Wikipedia, e.g. QA at CLEF 2006–2008 (Gillard et al., 2006). Such datasets focused mainly on Indo-European languages, though more recent ones also covered other languages, e.g. Hindi and Bengali at FIRE 2012 (Yadav et al., 2012).
There are wide range of monolingual reading comprehension datasets, many of them variants of SQuAD (Rajpurkar et al., 2016). Most of them are available in Chinese, Russian, and French and they generally consist of naturalistic data in each language.
Monolingual open-retrieval QA datasets are more diverse in nature. They differ based on the type and amount of context they provide and often focus on specialized domains, from Chinese history exams (Zhao & Zhao, 2018) to Chinese maternity forums (Xu et al., 2020) and Polish 'Did you know?' questions (Marcinczuk et al., 2013).
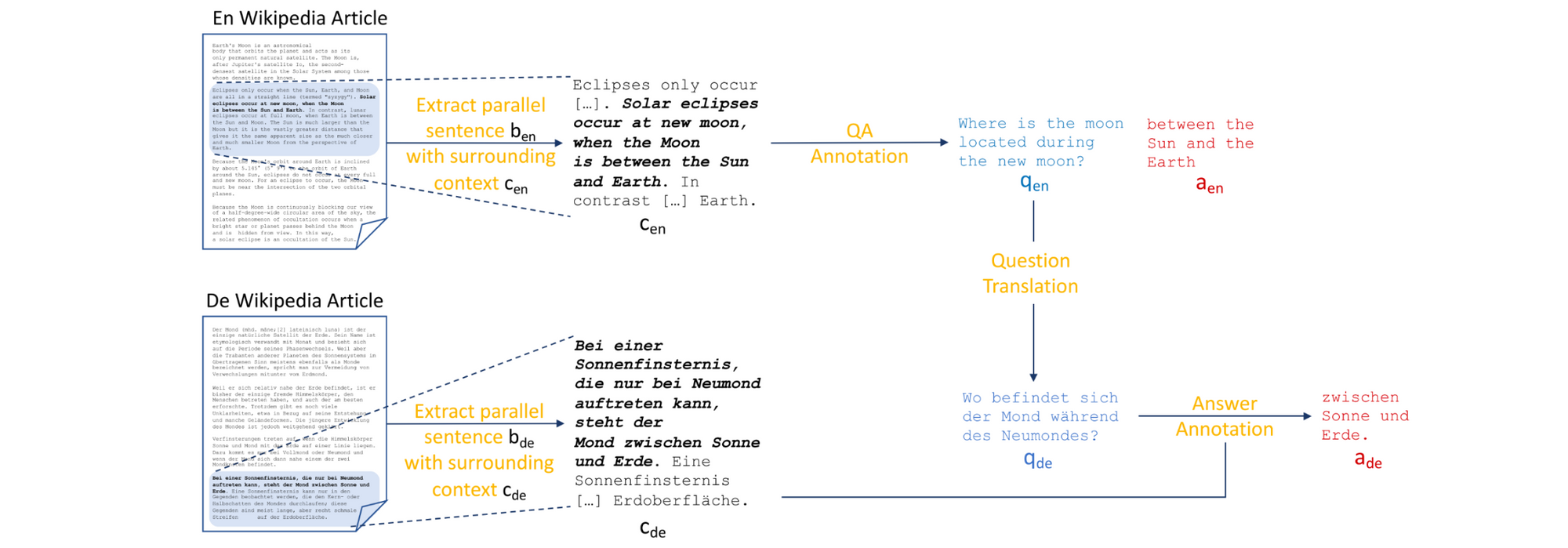
Multilingual reading comprehension datasets have generally been created using translations. MLQA (Lewis et al., 2020), which can be seen above has been created by automatically aligning Wikipedia paragraphs across multiple languages and annotating questions and answers on the aligned paragraphs. Such automatic alignment, however, may lead to severe quality issues for some languages (Caswell et al., 2021) and may result in overfitting to the biases of the alignment model. Another dataset, XQuAD (Artetxe et al., 2020) was created by professionally translating a subset of SQuAD to 10 other languages. Finally, MLQA-R and XQuAD-R (Roy et al., 2020) are conversions of the former datasets to the answer sentence retrieval setting.
Multilingual open-retrieval QA datasets typically consist of naturalistic data. XQA (Liu et al., 2019) covers 'Did you know?' Wikipedia questions converted to a Cloze format. For each question, the top 10 Wikipedia documents ranked by BM25 are provided as context. TyDi QA (Clark et al., 2020) ask annotators to write "information-seeking" questions based on short Wikipedia prompts in typologically diverse languages. Such information-seeking questions lead to less lexical overlap compared to RC datasets like MLQA and XQuAD and thus result in a more challenging QA setting. However, as in-language Wikipedias are used for finding context paragraphs (via Google Search) and as the Wikipedias of many under-represented languages are very small, many questions in TyDi QA are unanswerable.
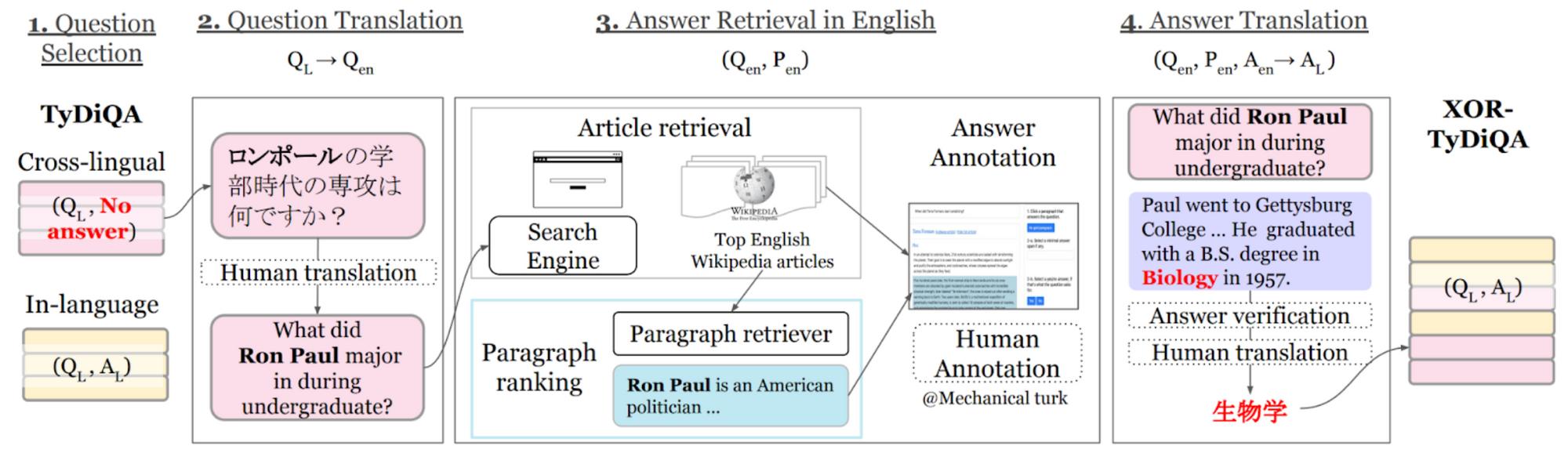
XOR-TyDi QA (Asai et al., 2021) addresses this issue via the above procedure, which translates unanswerable TyDi QA questions to English and retrieves context paragraphs from English Wikipedia. This strategy significantly decreases the fraction of unanswerable questions. While XOR-TyDi QA focuses on cross-lingual retrieval, Mr. TyDi (Zhang et al., 2021) augments TyDi QA with in-language documents for evaluating monolingual retrieval models. As answers in TyDi QA are spans in a sentence, Gen-TyDi QA (Muller et al., 2021) extends the dataset with human-generated answers to enable the evaluation of generative QA models. Finally, MKQA (Longpre et al., 2020) translates 10k queries from Natural Questions (Kwiatkowski et al., 2019) to 25 other languages. In addition, it augments the dataset with annotations that link directly against Wikidata entities, enabling evaluation beyond span extraction.
An emerging category of multilingual QA datasets is multilingual common sense reasoning. Such datasets consist of multiple-choice assertions that are translated into other languages (Ponti et al., 2020; Lin et al., 2021).
Issues of Multilingual QA Datasets
Existing monolingual and multilingual QA datasets have some issues that one should be aware of.
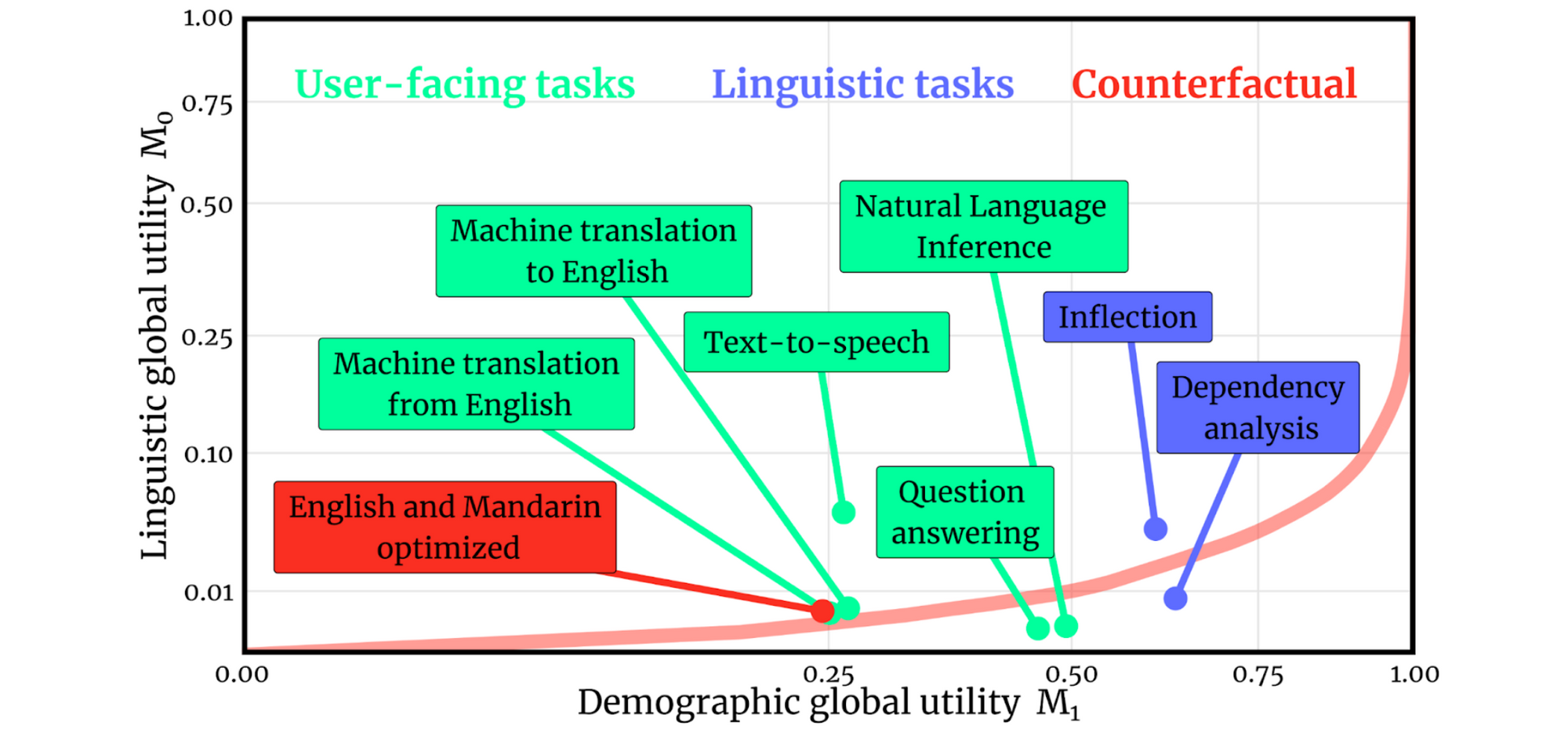
Language distribution Existing datasets predominantly focus on "high-resource" languages where large amounts of data are available. Evaluating QA models on such datasets provides a distorted view of progress in the field. For instance, questions that can be solved by string matching are easy in English but much harder in morphologically rich languages (Clark et al., 2020). Among current key applications of NLP, QA has the lowest linguistic global utility, i.e. performance averaged across the world's languages (Blasi et al., 2021), which can be seen below. While QA datasets cover languages with many speakers, there is still a long way to go in terms of an equitable coverage across the world's languages.
Homogeneity In order to make collection scalable, multilingual datasets often collect data that covers the same question or similar topics across languages, thus missing out on language-specific nuances. In addition, it is often not feasible to do an in-depth error analysis for every language. The most common source of homogeneity is translation, which carries its own biases.
Limitations of translation "Translationese" differs in many aspects from natural language (Volanksy et al., 2015). Translated questions often do not have answers in a target language Wikipedia (Valentim et al., 2021). In addition, datasets created via translation inherit artefacts such as a large train-test overlap of answers in NQ (Lewis et al., 2020) and translation also leads to new artefacts, e.g. in NLI when premise and hypothesis are translated separately (Artetxe et al., 2020). Finally, translated questions differ from the types of questions "naturally" asked by speakers of different languages, leading to an English and Western-centric bias.
English and Western-centric bias Examples in many QA datasets are biased towards questions asked by English speakers. Cultures differ in what types of questions are typically asked, e.g. speakers outside the US probably would not ask about famous American football or baseball players. In COPA (Roemmele et al., 2011), many referents have no language-specific terms in some languages, e.g. bowling ball, hamburger, lottery (Ponti et al., 2020). Common sense knowledge, social norms, taboo topics, assessments of social distance, etc are also culture-dependent (Thomas, 1983). Lastly, the common setting of training on English data leads to an overestimation of transfer performance on languages similar to English and underestimation on more distant languages.
Dependence on retrieval The standard setting of identifying a minimal span for open-domain QA in the retrieved documents benefits extractive systems. It assumes there is a single gold paragraph providing the correct answer and does not consider information from other paragraphs or pages. For unanswerable questions, answers may often be found in other pages that were not retrieved (Asai & Choi, 2021).
Information scarcity Typical knowledge resources such as language-specific Wikipedias often do not contain the relevant information, particularly for under-represented languages. For such languages, datasets must necessarily be cross-lingual. In addition, some information is only available from other sources, e.g. IMDb, news articles, etc.
Difficulty of multilingual comparison Comparing a model's performance across different languages is difficult due to a range of factors such as different levels of question difficulty, different amounts and quality of monolingual data, impact of translationese, etc. Instead, it is better to perform system-level comparisons across languages.
Monolingual vs multilingual QA datasets Creating multilingual QA datasets is expensive and thus often infeasible with academic budgets. In contrast, work on monolingual QA datasets is often perceived as "niche". Such work, however, is arguably much more important and impactful than incremental modelling advances, which are commonly accepted to conferences (Rogers et al., 2021). In order to foster inclusivity and diversity in NLP, it is key to enable and reward such work, particularly for under-represented languages. Language-specific QA datasets can go beyond a "replication" of English work by, for instance, performing analyses of language-specific phenomena and extending or improving the QA setting.
Creating QA Datasets
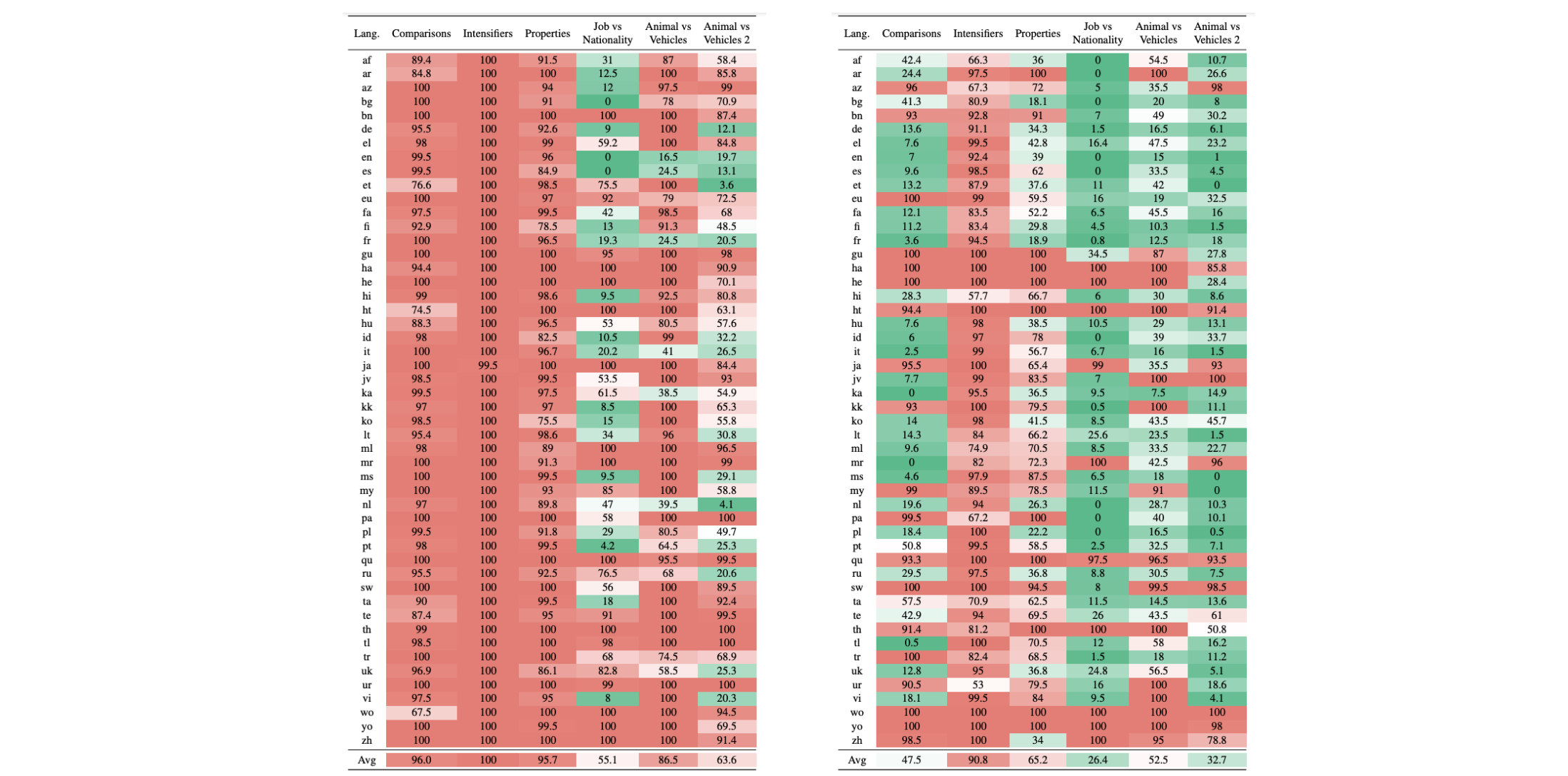
Efficient multilingual QA evaluation at scale A key challenge of multilingual QA is the lack of data for many languages. Instead of labelling large amounts of data in every language in order to cover the entire distribution, we can create targeted tests that probe for specific capabilities, for instance using CheckList (Ribeiro et al., 2020). This way, a small number of templates can cover many different model capabilities. Such template-based tests have so far been used for evaluating multilingual reading comprehension (Ruder et al., 2021) and closed-book QA (Jiang et al., 2020; Kassner et al., 2021) where they enable fine-grained evaluation across languages as can be seen below. However, in order to scale such tests across languages native speaker expertise or translation are still required.
Best practices When creating a new QA dataset, it is important to focus on the research questions you want to answer with your dataset. Try to avoid creating confounding variables (translationese, morphology, syntax, etc) that obfuscate answering these questions. Consider collecting data in a typologically diverse set of languages and think about the use case of your dataset and how systems based on the data could help humans. Chose an appropriate dataset format: If you want to help people around the world answer questions, focus on information-seeking questions and avoid cultural bias. If you want to help users ask questions about a short document, focus on reading comprehension. Finally, in order to create inclusive and diverse QA datasets, it is important to work with speaker communities and conduct participatory research (∀ et al., 2020).
Multilingual QA Evaluation
Common evaluation settings in multilingual QA range from monolingual QA where all data is in the same language to cross-lingual scenarios where the question, context, and answer can be in different languages as well as zero-shot cross-lingual transfer settings where training data is in a high-resource language and test data is in another language.
Evaluation metrics are based on lexical overlap using either Exact Match (EM) or mean token F1, with optional pre-processing of predictions and answers (Lewis et al., 2020). Such token-based metrics, however, are not appropriate for languages without whitespace separation and require a language-specific segmentation method, which introduces a dependence on the evaluation setting. Furthermore, metrics based on string matching penalize morphologically rich languages as extracted spans may contain irrelevant morphemes, favour extractive over generative systems, and are biased towards short answers.
Alternatively, evaluation can be performed on the character or byte level. As standard metrics used for natural language generation (NLG) such as BLEU or ROUGE show little correlation with human judgements for some languages (Muller et al., 2021), learned metrics based on strong pre-trained models such as BERTScore (Zhang et al., 2020) or SAS (Risch et al., 2021) may be preferred, particularly for evaluating generative models.
Multilingual QA Models
Multilingual models for QA are generally based on pre-trained multilingual Transformers such as mBERT (Devlin et al., 2019), XLM-R (Conneau et al., 2020), or mT5 (Xue et al., 2021).
Models for Multilingual Reading Comprehension
For reading comprehension, a multilingual model is typically fine-tuned on data in English and then applied to test data in the target language via zero-shot transfer. Recent models generally perform well on high-resource languages present in standard QA datasets while performance is slightly lower for languages with different scripts (Ruder et al., 2021), which can be seen below. Fine-tuning the model on data in the target language using masked language modelling (MLM) before training on task-specific data generally improves performance (Pfeiffer et al., 2020).

In practice, fine-tuning on a few labelled target language examples can significantly improve transfer performance compared to zero-shot transfer (Hu et al., 2020; Lauscher et al., 2020). However, the same does not hold for the more challenging open-retrieval QA (Kirstain et al., 2021). Multi-task training on data in many languages improves performance further (Debnath et al., 2021).
Most prior work on multilingual QA uses the translate-test setting, which translates all data into English—typically using an online MT system as a black box—and then applies a QA model trained on English to it (Hartrumpf et al., 2008; Lin & Kuo, 2010; Shima & Mitamura, 2010). In order to map the predicted English answer to the target language, back-translation of the answer span does not work well as it is agnostic of the paragraph context. Instead, recent methods employ the attention weights from a neural MT system to align the English answer span to a span in the original document (Asai et al., 2018; Lewis et al., 2020).
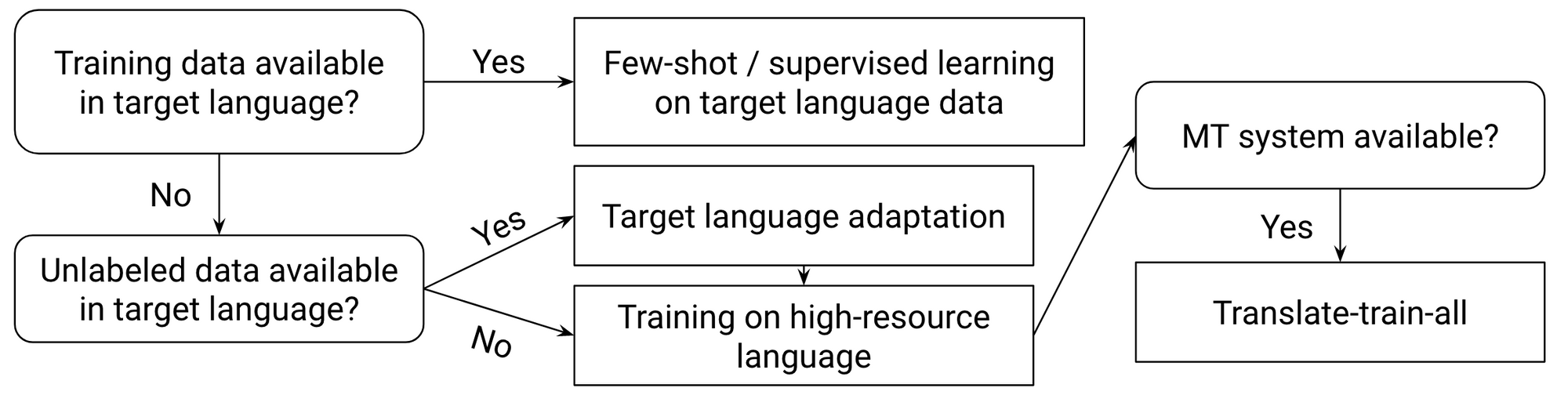
Alternatively, in the translate-train setting the English training data is translated to the target language and a target language QA model is trained on the data. In this case, it is crucial to ensure that answer spans can be recovered after translation by enclosing them with tags or using fuzzy search (Hsu et al., 2019; Hu et al., 2020). We can go even further and translate the English data to all target languages on which we train a multilingual QA model. This translate-train-all setting generally performs best for reading comprehension (Conneau et al., 2020; Hu et al., 2020; Ruder et al., 2021) and achieves performance close to English on high-resource languages but lower on others. The below flowchart shows what method achieves the best performance depending on the available data.
Models for Multilingual Open-Retrieval QA
Translate-test is the standard approach for open-retrieval QA as it only requires access to English resources. In addition to training a document reader model on English data, the open-retrieval setting also necessitates training an English retrieval model. During inference, we apply the models to the translated data and back-translate the answer to the target language, which can be seen below. However, low-quality MT may lead to error propagation and for some questions answers may not be available in the English Wikipedia. On the other hand, translate-train is generally infeasible in the open-retrieval setting as it requires translating all possible context (such as the entire Wikipedia) to the target language. As an alternative, only questions can be translated, which may outperform translate-test (Longpre et al., 2020).
Without using translations, we need to train cross-lingual retrieval and document reader models that can assess similarity between questions and context paragraphs and answer spans respectively across languages. To this end, we need to fine-tune a pre-trained multilingual model using target language questions and English contexts. However, restricting retrieval to English documents limits the viewpoints and knowledge sources at our disposal. We would thus like to extend retrieval to documents in multiple languages.
Fine-tuning a pre-trained multilingual model to retrieve passages only on English data does not generalize well to other languages (Zhang et al., 2021), similar to the multi-domain setting. In order to train a retrieval model that better generalizes to other languages, we can fine-tune the model on multilingual data instead (Asai et al., 2021). Alternatively, we can employ data augmentation. Similar to the multi-domain setting, we can obtain silver data in the target language by generating synthetic target language questions, in this case using a translate-train model (Shi et al., 2021). In addition, we can obtain weakly supervised examples using language links in Wikipedia as can be seen below (Shi et al., 2021; Asai et al., 2021). Specifically, we retrieve the articles corresponding to the original answer and answer paragraph in other languages and use them as new training examples. Lastly, a combination of BM25 + dense retrieval also performs best in this setting (Zhang et al., 2021).

To aggregate the retrieved passages in different languages we can train a pre-trained multilingual text-to-text model such as mT5 to generate an answer when provided with the passages as input (Muller et al., 2021; Asai et al., 2021). The full pipeline consisting of multilingual retrieval and answer generation models can be seen below. As the model will only learn to generate answers in languages covered by existing datasets, data augmentation is again key. Furthermore, models can be iteratively trained using newly retrieved and newly identified answers as additional training data in subsequent iterations (Asai et al., 2021). The best models achieve strong performance in the full open-retrieval setting but there is still significant headroom left.
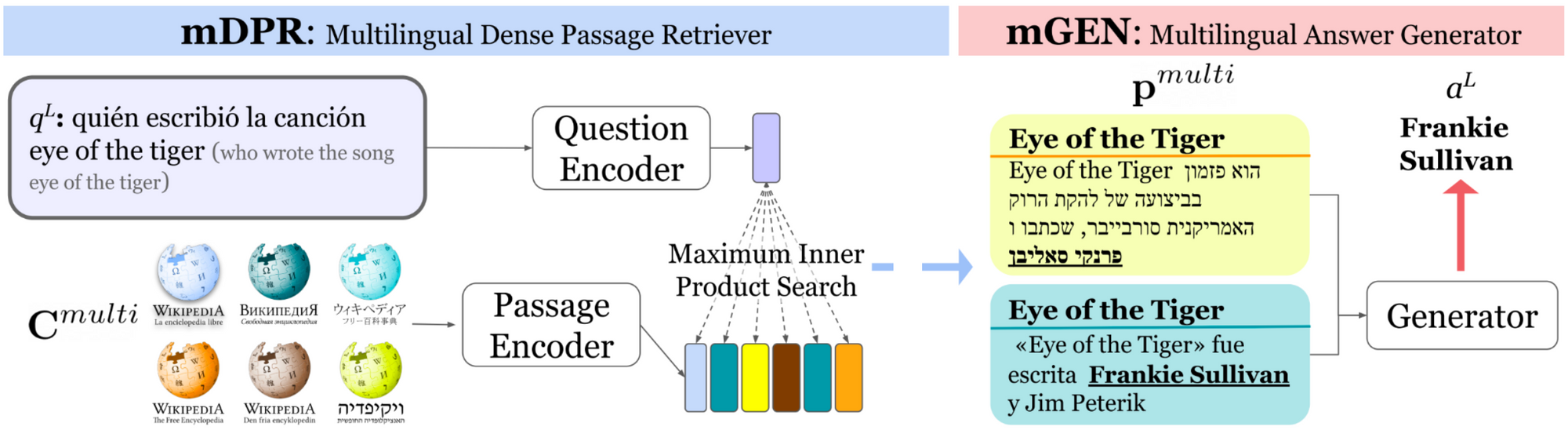
Two of the most challenging aspects of multilingual open-retrieval QA are finding the paragraph containing the answer (paragraph selection) and identifying whether a document contains the answer to a query (answerability prediction; Asai & Choi, 2021). A related problem is answer sentence selection where models predict whether a sentence contains the answer (Garg et al., 2020). Unanswerability is often due to errors in document retrieval or unanswerable questions requiring multiple paragraphs to answer. To address this headroom, Asai and Choi (2021) recommend to a) go beyond using Wikipedia for retrieval; b) to improve the quality of annotated questions in existing and future datasets; and c) to move from extracting a span to generating the answer.
Open Research Directions
Multi-modal question answering For many language varieties and domains, it may be easier to obtain data in other modalities. As a recent example, SD-QA (Faisal et al., 2021) augments TyDi QA with spoken utterances matching the questions in four languages and multiple dialects.
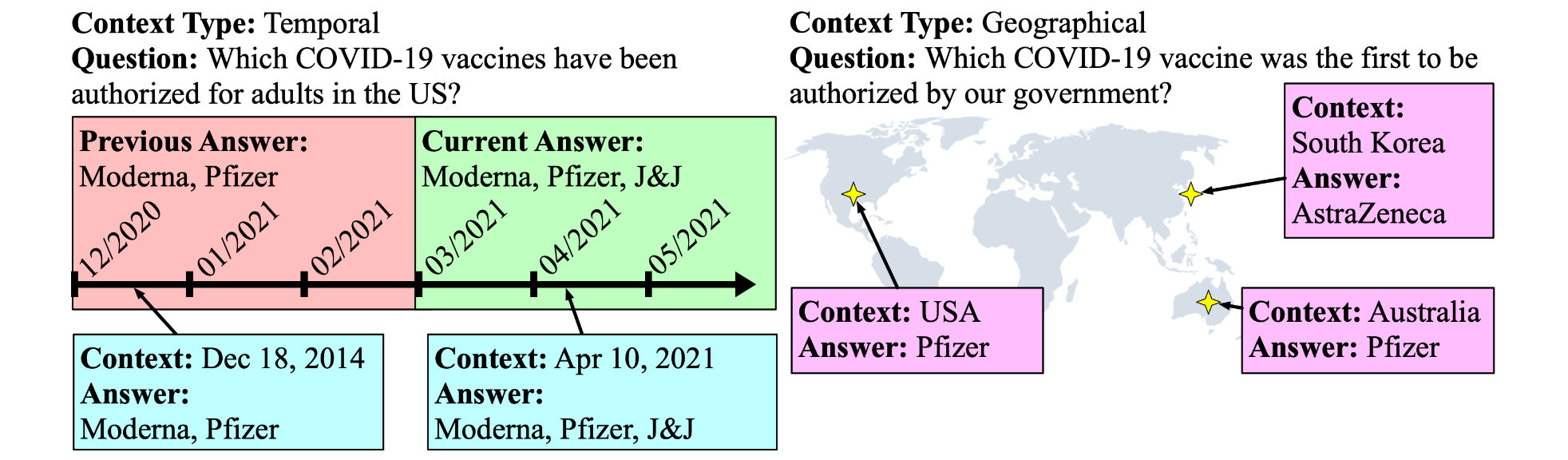
Other domains: time and geography A domain can include many facets not covered in existing work. For instance, answers often depend on extra-linguistic context such as the time and location where the questions were asked. SituatedQA (Zhang & Choi, 2021) augments context-dependent questions in Natural Questions with time and geography-dependent contexts to study such questions.
Code-switching Code-switching is a common phenomenon in multilingual communities but mostly neglected in QA research. Only few resources exist in Bengali, Hindi, Telugu, and Tamil (Raghavi et al., 2015; Banerjee et al., 2016; Chandu et al., 2018; Gupta et al., 2018). For a broader overview of code-switching, have a look at this survey (Doğruöz et al., 2021).
Multilingual multi-domain generalization Most open-retrieval QA datasets only cover Wikipedia while many domains important in real-world applications (e.g. tech questions) only have English QA datasets. Other domains without much data are particularly relevant in non-Western contexts, e.g. finance for small businesses, legal and health questions. In addition, currently unanswerable questions require retrieving information from a wider set of domains such as IMDb (Asai et al., 2021). In order to create truly open-domain QA systems, we thus need to train open-retrieval QA systems to answer questions from many different domains.
Data augmentation Generation of synthetic multilingual QA data has been little explored beyond translation and retrieval (Shi et al., 2021). The generation of data about non-Western entities may be particularly helpful.
Generative question answering In most existing QA datasets, the short answer is a span in the context. In order to train and evaluate models more effectively, more datasets need to include longer, more natural answers. The generation of long-form answers is particularly challenging, however (Krishna et al., 2021).
Aggregating evidence from diverse sources We need to develop better aggregation methods that cover reasoning paths, e.g. for multi-hope reasoning (Asai et al., 2020). Models also need to be able to generate answers that are faithful to the retrieved passages, requiring clear answer attribution. Finally, we require methods that can effectively combine evidence from different domains and even different modalities.
Conversational question answering Current open-retrieval QA datasets are generally single-turn and do not depend on any external context. In order to train generally useful QA systems, models should also be able to take into account conversational context as required by datasets such as QuAC (Choi et al., 2018). In particular, they should be able to handle coreference, ask for clarification regarding ambiguous questions, etc.
Further reading
Here are some additional resources that may be useful to learn more about different aspects of the topic:
- a survey on question answering datasets with a particular focus on the required reasoning skills (Rogers et al., 2021);
- a survey on neural unsupervised domain adaptation in NLP (Ramponi & Plank, 2020);
- the ACL 2020 tutorial on open-domain question answering;
- and my ACL 2019 tutorial on cross-lingual representation learning.
Credit
Thanks to the following people for feedback on a draft of the tutorial slides: Jon Clark, Tim Möller, Sara Rosenthal, Md Arafat Sultan, and Benjamin Muller.
Citation
If you found this post helpful, consider citing the tutorial as:
@inproceedings{ruder-sil-2021-multi,
title = "Multi-Domain Multilingual Question Answering",
author = "Ruder, Sebastian and
Sil, Avi",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic {\&} Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-tutorials.4",
pages = "17--21",
}