NAACL 2019 Highlights
This post discusses highlights of NAACL 2019. It covers transfer learning, common sense reasoning, natural language generation, bias, non-English languages, and diversity and inclusion.


Update 19.04.20: Added a translation of this post in Spanish.
This post discusses highlights of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2019).
You can find past highlights of conferences here. The conference accepted 424 papers (which you can find here) and had 1575 participants (see the opening session slides for more details). These are the topics that stuck out for me most:
- Transfer learning
- Common sense reasoning
- Natural language generation
- Bias
- Non-English languages
- Diversity and inclusion
Transfer learning
Interest in transfer learning remains high. The Transfer Learning in NLP tutorial (pictured above and organized by Matthew Peters, Swabha Swayamdipta, Thomas Wolf, and me) was packed. NAACL 2019 awarded the best long paper award to BERT, arguably the most impactful recent transfer learning method. Despite its recency, conference papers already leveraged BERT for aspect-based sentiment analysis, review reading comprehension, common sense reasoning, and open-domain question answering.
At the RepEval workshop, Kristina Toutanova discussed how to use transfer learning for open-domain question answering. With appropriate pretraining using an Inverse Cloze Task, the retriever and reader can be fine-tuned directly on QA pairs without an intermediate IR system. This demonstrates that a careful initialization + fine-tuning are two key ingredients for transfer learning and work even on challenging tasks. This has also been shown in the past for learning cross-lingual word embeddings and unsupervised MT. She also made the point that single-vector sentence/paragraph representations are very useful for retrieval—and that we should continue to work on them. Overall, there are many exciting research directions in transfer learning in NLP, some of which we outlined at the end of our tutorial. My other highlights include:
- Single-step Auxiliary loss Transfer Learning (SiATL; Chronopoulou et al.), an "embarrassingly simple" approach that reduces some of the complexity of ULMFiT via multi-task learning and exponentially decaying the auxiliary loss.
- AutoSeM (Guo et al.), a two-stage pipeline for multi-task learning that utilizes multi-armed bandits and Bayesian optimization to learn the best auxiliary task and the best task mixing ratio respectively.
- An evaluation of contextual representation across 16 tasks (Liu et al.) that shows that they are bad at capturing fine-grained linguistic knowledge and higher layers in RNNs are more task-specific than in Transformers.
Common sense reasoning
Language modelling is a pretraining task that has been shown to learn generally useful representations at scale. However, there are some things that are simply never written, even in billions of tokens. Overcoming this reporting bias is a key challenge in adapting language models to more complex tasks. To test reasoning with knowledge that is often left unsaid, the best resource paper used the common sense knowledge base ConceptNet as “seed”. They created CommonsenseQA, a dataset of multiple-choice questions where most answers have the same relation to the target concept (see below).

This requires the model to use common sense rather than just relational or co-occurrence information to answer the question. BERT achieves 55.9% accuracy on this dataset—and is estimated to achieve around 75% with 100k examples—still well below human performance 88.9%. What does it take to get to those 88.9%? Most likely structured knowledge, interactive and multimodal learning. In his talk at the Workshop on Shortcomings in Vision and Language (SiLV), Yoav Artzi discussed language diversity in grounded NLU, noting that we need to move from synthetic to more realistic images for learning grounded representations.
Another prerequisite for natural language understanding is compositional reasoning. The Deep Learning for Natural Language Inference tutorial discussed natural language inference, a common benchmark for evaluating such forms of reasoning in-depth. I particularly liked the following papers:
- A label consistency framework for procedural text comprehension (Du et al.) that encourages consistency between predictions from descriptions of the same process. This is a clever way to use intuition and additional data to incorporate an inductive bias into the model.
- Discrete Reasoning Over the content of Paragraphs (DROP; Dua et al.), which requires models to resolve references in a question and perform discrete operations (e.g. addition, counting, sorting) over multiple referents in the text.
Natural language generation
At the NeuralGen workshop, Graham Neubig discussed methods to optimize a non-differentiable objective function such as BLEU directly, including minimum risk training and REINFORCE and tricks to deal with their instability and get them to work. While we had touched on transfer learning for natural language generation (NLG) in our tutorial, Sasha Rush provided many more details and discussed different methods of using language models to improve NLG quality. Another way to improve sample quality is to focus on decoding. Yejin Choi discussed a new sampling method that samples from the head of the distribution and leads to better text quality. She also discussed the generation of fake news and how large pretrained language models such as Grover can be used to defend against them.
Generative adversarial networks (GANs) are a popular way to generate images, but so far have underperformed for language. The Deep Adversarial Learning for NLP tutorial argued that we should not give up on them as the unsupervised or self-supervised learning done by GANs has many applications in NLP.
Another compelling aspect of generation is to enable multiple agents to communicate effectively. Besides providing a window into how language emerges, it may be necessary for interactive learning and to transfer knowledge among agents. Angeliki Lazaridou discussed in her SiLV workshop talk that deep reinforcement learning tools seem to work well for this setting but argued that better biases are needed. In addition, it is still difficult to interface emergent language to natural language.
I also enjoyed the following papers:
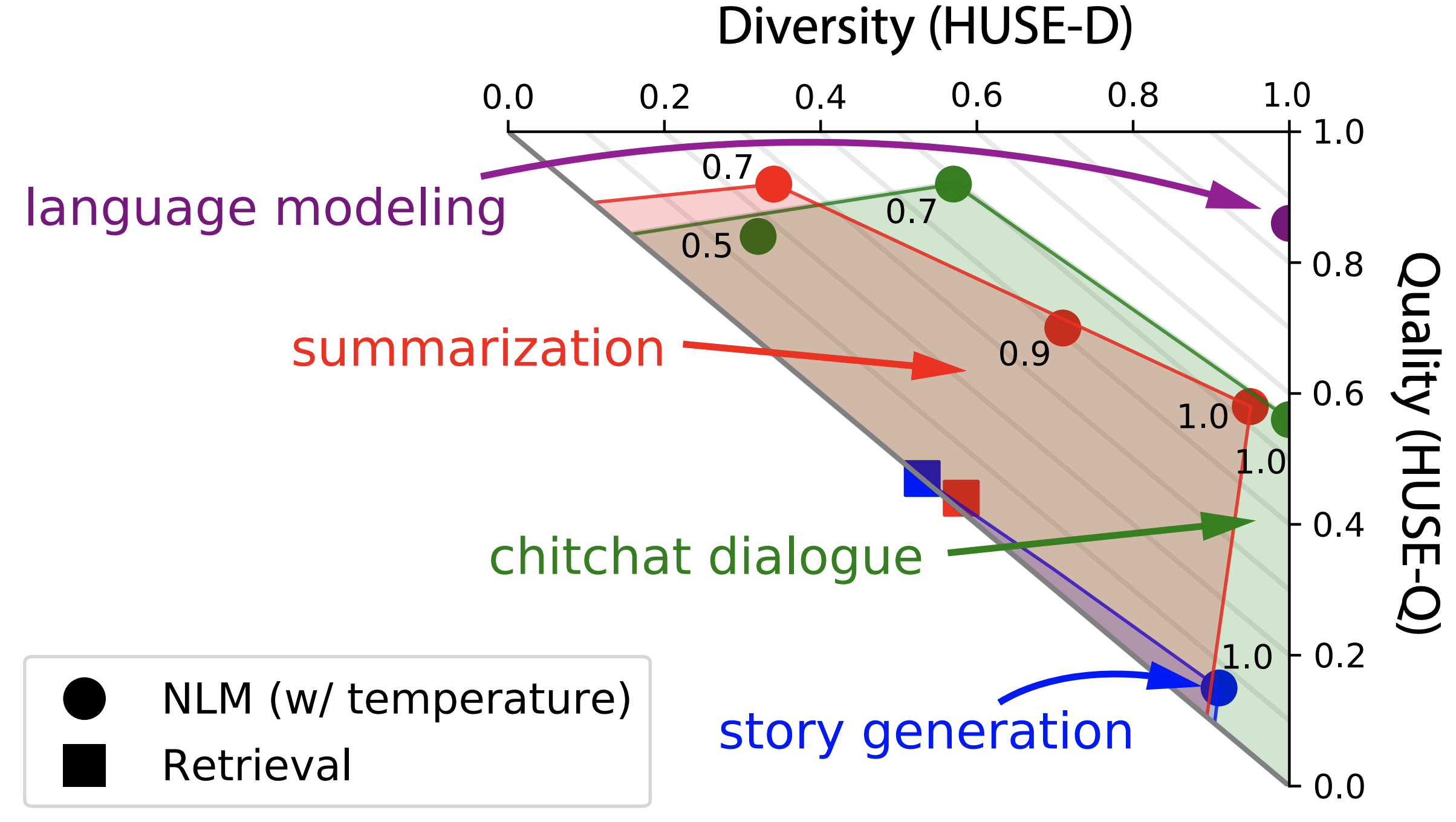
- Human Unified with Statistical Evaluation (HUSE; Hashimoto et al.), a new metric for natural language generation that can consider both diversity and quality and yields a Pareto frontier by trading off one of the two (see above). Methods such as temperature annealing result in higher quality, but reduce diversity.
- Separating planning from realization (Moryossef et al.) can improve the quality of generated text from structured data such as RDF triplets as there are often multiple ways structured information can be realized in text.
- Decoupling syntax and surface form generation (Cao & Clark) is another way to deal with the underspecified problem of text generation from structured data (in this case, abstract meaning representations).
- A systematic analysis that probes how useful the visual modality actually is for multimodal translation (Caglayan et al.) and was awarded the best short paper award. It observes that models with less textual information more strongly rely on the visual context, contrary to current beliefs.
Bias
The theme of the conference was model bias. The diverse sets of keynotes fit very well into this theme. The first keynote by Arvind Narayanan in particular highlighted one under-appreciated aspect of bias, i.e. that we can leverage the bias in our models to improve our understanding of human culture.
On the whole, there is a fine line between desirable and undesirable bias. We often try to encode inductive bias about how the world works, such as objects being invariant to translation. On the other hand, we do not want our models to learn superficial cues or relations that are not part of our possibly idealized perception of the world, such as gender bias. Ultimately, super-human performance should not just entail that models outperform humans quantitively but also that they are less biased and fallible.
Lastly, we should be conscious that technology has lasting impact in the real world. As one vivid example of this, Kieran Snyder recounted in her keynote the time when she had to design a sorting algorithm for Sinhala (see below). Sorting Sinhalese names was necessary for the Sri Lankan government to be able to search for survivors in the aftermath of the 2004 tsunami. Her decision on how to alphabetize the language later became part of an official government policy.

Some of my favourite papers on bias include:
- Debiasing methods only superficially remove bias in word embeddings (Gonen & Goldberg); bias is still reflected in—and can be recovered from—the distances in the debiased embeddings.
- An evaluation of bias in contextualized word embeddings (Zhao et al.) finds that ELMo syntactically and unequally encodes gender information and—more importantly—that this bias is inherited by downstream models, such as a coreference system.
Non-English languages
On the topic of different languages, during the conference, the “Bender Rule”—named after Emily Bender who is known for her advocacy for multilingual language processing, among other things—was frequently invoked after presentations. In short, the rule states: "Always name the language(s) you are working on." Not explicitly identifying the language under consideration leads to English being perceived as the default and as proxy for other languages, which is problematic in many ways (see Emily's slides for a thorough rationale).
In this vein, some of my favourite papers from the conference investigate how the performance of our models changes as we apply them other languages:
- Polyglot contextual representations (Mulcaire et al.) that are trained on English and an additional language by initializing word embeddings with cross-lingual representations. For some settings (Chinese SRL, Arabic NER), cross-lingual training yields large improvements.
- A study on transfer of dependency parsers trained on English to 30 other languages (Ahmad et al.) finds that RNNs trained on English transfer well to languages close to English, but self-attention models transfer better to distant languages.
- An unsupervised POS tagger for low-resource languages (Cardenas et al.) that "deciphers" Brown cluster ids in order to generate the POS sequence and achieves state-of-the-art performance on Sinhalese (see above).
Diversity and inclusion
As the community is growing it is important that new members feel included and that their voices are heard. NAACL 2019 put into effect a wide range of initiatives in this regard, from thoughtful touches such as badge stickers (see above) to matching newcomers with mentors and “big siblings”, to fundamental ones such as childcare (see below) and live captions. I particularly appreciated the live tweeting, which made the conference accessible to people who could not attend.

Translations
This post has been translated into the following languages:
Cover image: The room at the Transfer Learning in NLP tutorial (Image credit: Dan Simonson)